Spark3内核源码与优化
一、Spark内核原理
1、Spark 内核概述
1.1 简介
Spark 内核泛指 Spark 的核心运行机制,包括 Spark 核心组件的运行机制、Spark 任务调度机制、Spark 内存管理机制、Spark 核心功能的运行原理等,熟练掌握 Spark 内核原理,能够帮助我们更好地完成 Spark 代码设计,并能够帮助我们准确锁定项目运行过程中出现的问题的症结所在

Spark 内核泛指 Spark 的核心运行机制,包括 Spark 核心组件的运行机制、Spark 任务调度机制、Spark 内存管理机制、Spark 核心功能的运行原理等,熟练掌握 Spark 内核原理,能够帮助我们更好地完成 Spark 代码设计,并能够帮助我们准确锁定项目运行过程中出现的问题的症结所在
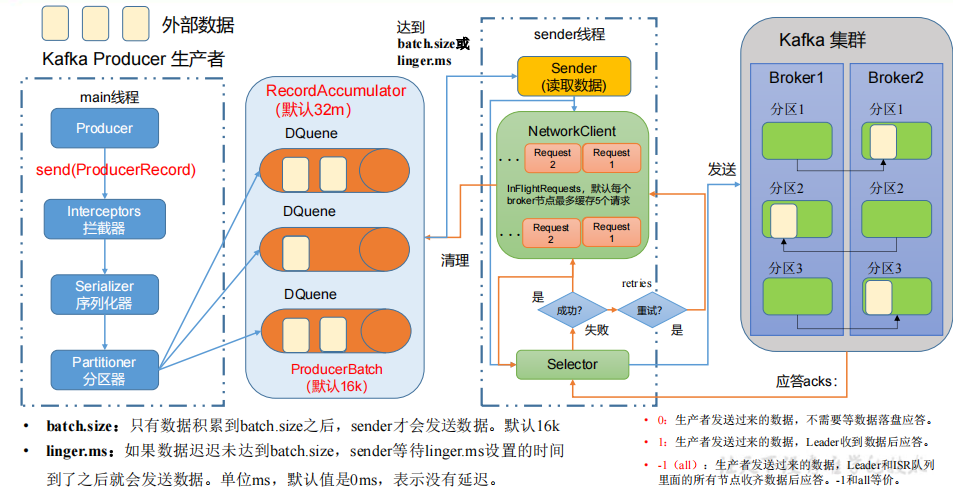
Kafka是 一个开源的 分布式事件流平台 (Event StreamingPlatform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序
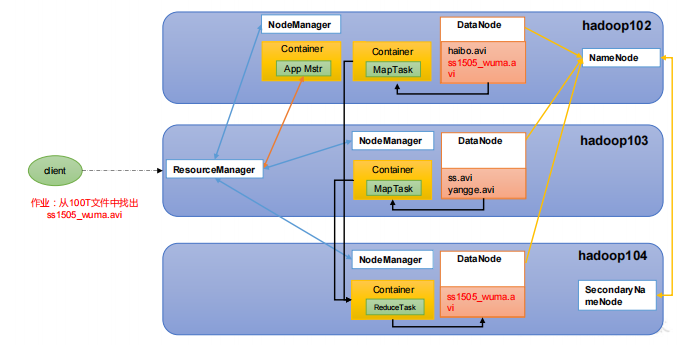
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。

Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。Flume最主要的作用就是,实时读取服务器本地磁盘的数据(或者网络端口数据),将数据写入到HDFS
Zabbix是一款能够监控各种网络参数以及服务器健康性和完整性的软件。Zabbix使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警。这样可以快速反馈服务器的问题。基于已存储的数据,Zabbix提供了出色的报告和数据可视化功能
官方文档:https://www.mongodb.com/docs/manual/
菜鸟教程:https://www.runoob.com/mongodb/mongodb-tutorial.html
MongoDB是一个基于分布式文件存储的数据库(支持集群、分片处理)。由C++语言编写。旨在为WEB应用提供可扩展高性能的数据存储解决方案。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
<br/><br/><br/>心怀天下<br/>只认真生活<br/>自信微笑面对未来