
MongoDB5.x学习笔记
MongoDB5.x学习笔记
一、概述
官方文档:https://www.mongodb.com/docs/manual/
菜鸟教程:https://www.runoob.com/mongodb/mongodb-tutorial.html
1、MongoDB简介
1.1 简介
MongoDB是一个基于分布式文件存储的数据库(支持集群、分片处理)。由C++语言编写。旨在为WEB应用提供可扩展高性能的数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品(偏向于非关系型数据库NoSQL),是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式(对json进行扩展),因此可以存储比较复杂的数据类型。MongoDB最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
总结: mongoDB是一个非关系型文档数据库
1.2 发展历史
- 2009年2月,MongoDB数据库首次在数据库领域亮相,打破了关系型数据库一统天下的局面;
- 2010年8月, MongoDB 1.6发布。这个版本最大的一个功能就是Sharding—自动分片;
- 2014年12月, MongoDB 3.0发布。由于收购了WiredTiger 存储引擎,大幅提升了MongoDB的写入性能;
- 2015年12月,3.2版本发布,开始支持了关系型数据库的核心功能:关联。你可以一次同时查询多个MongoDB的集合。
- 2016年, MongoDB推出Atlas,在AWS、 Azure 和GCP上的MongoDB托管服务;
- 2017年10月,MongoDB成功在纳斯达克敲钟,成为26年来第一家以数据库产品为主要业务的上市公司。
- 2018年6月, MongoDB4.0 发布推出ACID事务支持,成为第一个支持强事务的NoSQL数据库;
- 2018年–至今,MongoDB已经从一个在数据库领域籍籍无名的“小透明”,变成了话题度和热度都很高的“流量”数据库。
1.3 特点
- 面向集合存储,易存储对象类型的数据
- 支持查询以及动态查询
- 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言
- 文件存储格式为BSON(一种JSON的扩展)
- 支持复制和故障恢复和分片
- 支持事务支持(要求性不高,不能完全取代关系型数据库)
- 索引、聚合、关联
1.4 应用场景
- 游戏应用:使用云数据库MongoDB作为游戏服务器的数据库存储用户信息。用户的游戏装备、积分等直接以内嵌文档的形式存储,方便进行查询与更新
- 物流应用:使用云数据库MongoDB存储订单信息,订单状态在运送过程中会不断更新,以云数据库MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来,方便快捷且一目了然
- 社交应用:使用云数据库MongoDB存储用户信息以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。并且,云数据库MongoDB非常适合用来存储聊天记录,因为它提供了非常丰富的查询,并在写入和读取方面都相对较快
- 视频直播:使用云数据库MongoDB存储用户信息、礼物信息等。
- 大数据应用:使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态
2、MongoDB安装
2.1 原生安装
1 | wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu2004-5.0.19.tgz |
下面是5.0.5版本和4.4.10版本配置文件启动,可以进行参考,机器环境为centos
1 | # ======================5.05=========================== |
2.2 docker安装
1 | docker pull mongo:5.0.18 |
2.3 快捷安装
1 | # 安装 MongoDB |
二、核心概念
1、概述
库<DataBase>
mongodb中的库就类似于传统关系型数据库中库的概念,用来通过不同库隔离不同应用数据。 mongodb中可以建立多个数据库。每一个库都有自己的集合和权限,不同的数据库也放置在不同的文件中。默认的数据库为"test",数据库存储在启动指定的data目录中。
**集合<Collection>**集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表的概念。集合存在于数据库中,一个库中可以创建多个集合。每个集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性
文档<Document>
文档集合中一条条记录,是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
| RDBMS | MongoDB |
|---|---|
| 数据库<database> | 数据库<database> |
| 表<table> | 集合<collection> |
| 行<row> | 文档<document> |
| 列<colume> | 字段<field> |
2、数据库常用操作
2.1 库和集合操作
1 | # 首先进入客户端 |
2.2 文档操作
1 | # ========================插入文档================== |
2.3 文档查询
1 | # MongoDB 查询文档使用 find() 方法。find() 方法以非结构化的方式来显示所有文档。 |
2.4 $type
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果
1 | # 如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令 |
3、索引<index>
3.1 原理
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。 默认_id已经创建了索引
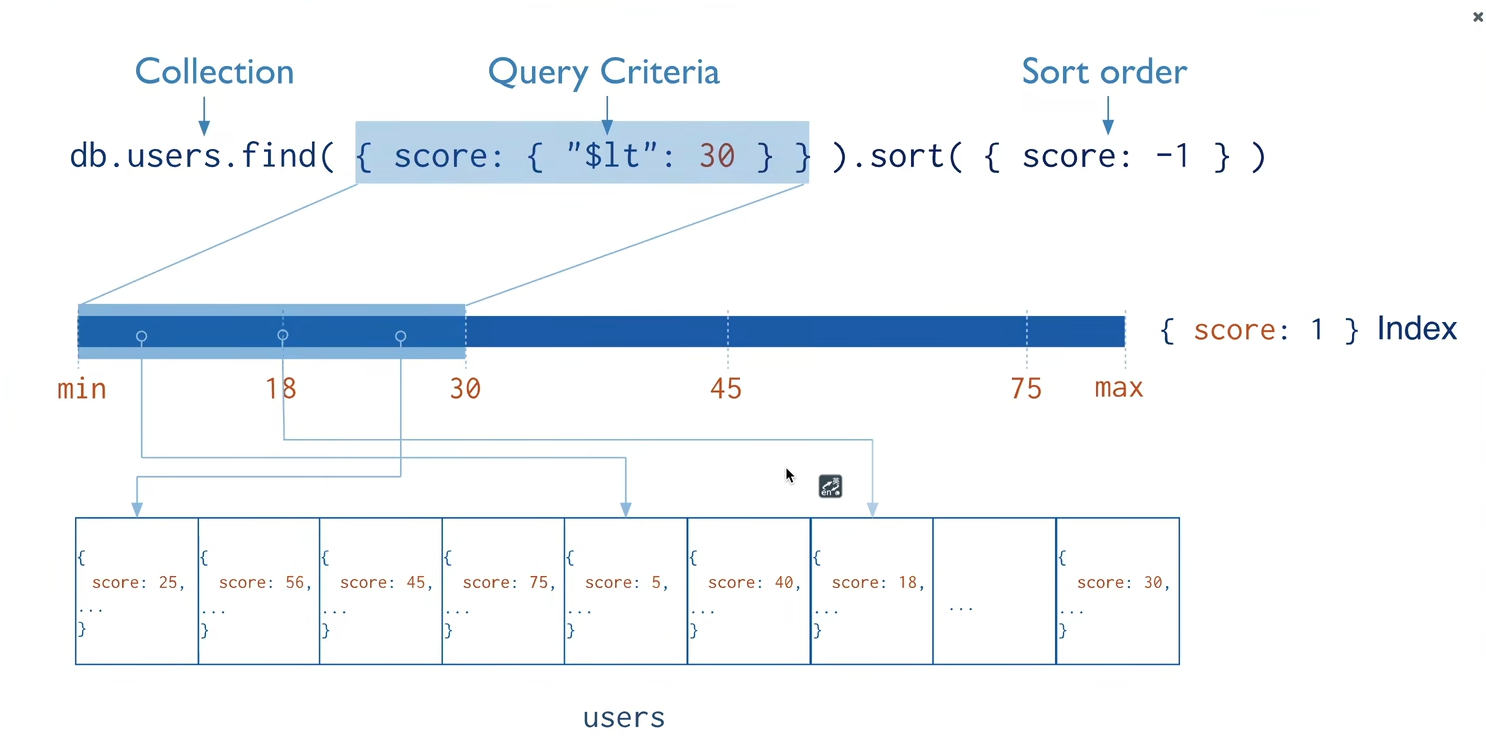
3.2 索引操作
1 | # 索引创建 |
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
3.3 复合索引
一个索引的值是由多个 key 进行维护的索引的称之为复合索引
1 | db.集合名称.createIndex({"title":1,"description":-1}) |
4、聚合<aggregate>
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似 SQL 语句中的 count(*)
1 | # 测试用例 |
常见聚合表达式
1 | # $sum,计算总和 |
三、应用整合
1、SpringBoot整合
1.1 环境配置
创建springboot工程羡慕,引入依赖
1 | <dependency> |
编写配置
1 | # mongodb 没有开启任何安全协议 |
1.2 集合操作
1 | // 创建集合 |
1.3 相关注解
Java–>对象–>JSON–>MongoDB
@Document 对应 类
- 修饰范围: 用在类上
- 作用: 用来映射这个类的一个对象为 mongo 中一条文档数据
- 属性:(value 、collection )用来指定操作的集合名称
@Id 对应 要指定为_id的变量名
- 修饰范围: 用在成员变量、方法上,只能出现一次
- 作用: 用来将成员变量的值映射为文档的_id 的值
@Field 对应 剩余变量名(变量名都按照类中属性名定义时,可以不指定,即同名时可不指定)
- 修饰范围: 用在成员变量、方法上
- 作用: 用来将成员变量以及值映射为文档中一个key、value对
- 属性: ( name,value)用来指定在文档中 key 的名称,默认为成员变量名
@Transient 不参与文档转换
- 修饰范围: 用在成员变量、方法上
- 作用 : 用来指定改成员变量,不参与文档的序列化
1 | mongoTemplate.insert(new User(4, "小wangb", 22, new Date()), "db1"); |
1.4 文档查询
1 | //根据id查询 |
1.5 文档更新&删除
1 | // ====== 更新 ==== |
四、权限配置与可视化
1、概述
刚安装完毕的mongodb默认不使用权限认证方式启动,与MySQL不同,mongodb在安装的时候并没有设置权限,然而公网运行系统需要设置权限以保证数据安全。MongoDB是没有默认管理员账号,所以要先添加管理员账号,并且mongodb服务器需要在运行的时候开启验证模式
- 用户只能在用户所在数据库登录(创建用户的数据库),包括管理员账号。
- 管理员可以管理所有数据库,但是不能直接管理其他数据库,要先认证后才可以。
2、权限管理
2.1 创建账户
1 | # 进入mongodb的shell |
2.2 账户常用操作
1 | # 查看创建的用户 |
2.3 权限启动认证
1 | # 启用权限验证 |
3、Docker启动认证
3.1 创建管理员
1 | # 创建一个文件夹用于存放数据,具体路径根据你自己想法来。这里这是举例。 |
3.2 创建 MongoDB 镜像 - 带验证
1 | # 创建容器 - 有校验 |
4、MongoDB可视化
1 | docker run -d \ |
五、副本与集群
1、副本集
1.1 概述
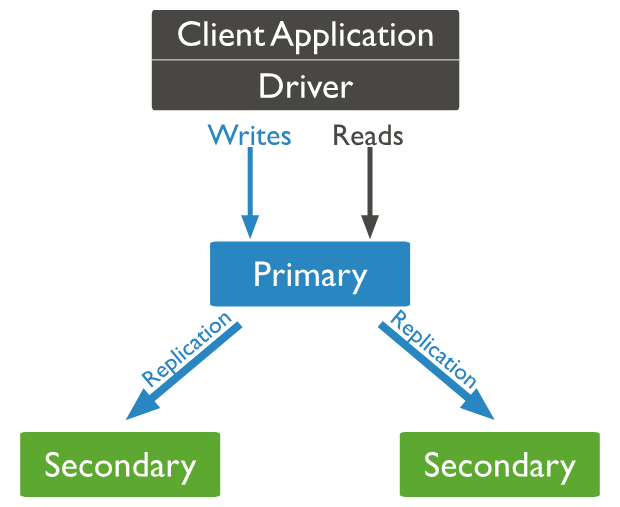
MongoDB 副本集(Replica Set)是有自动故障恢复功能的主从集群,有一个Primary节点和一个或多个Secondary节点组成。副本集没有固定的主节点,当主节点发生故障时整个集群会选举一个主节点为系统提供服务以保证系统的高可用。注意:这种方式并不能解决主节点的单点访问压力问题。
**注意:**当MongoDB副本集架构只剩一个节点时,整个节点是不可用的。单主不可写
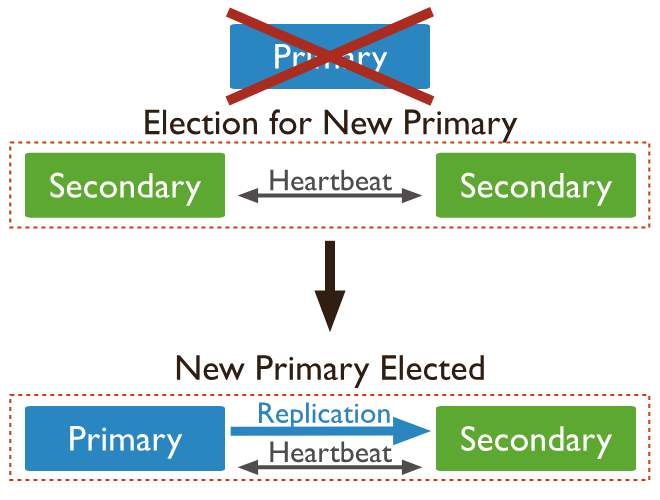
1.2 自动故障转移
当主节点未与集合的其他成员通信超过配置的选举超时时间(默认为 10 秒)时,合格的辅助节点将调用选举以将自己提名为新的主节点。集群尝试完成新主节点的选举并恢复正常操作。
1.3 副本集搭建
1 | # 这里我是用了一台机器,可以分作不同机器,注意ip即可 |
还有一种方式是配置文件
1 | ## 检查端口运行情况 如果正在运行 关闭服务 |
2、分片集群(sharing cluster)
2.1 概述
分片(sharding)是指将数据拆分,将其分散存在不同机器的过程,有时也用分区(partitioning)来表示这个概念,将数据分散在不同的机器上,不需要功能强大的大型计算机就能存储更多的数据,处理更大的负载。
分片目的是通过分片能够增加更多机器来应对不断的增加负载和数据,还不影响应用运行。MongoDB支持自动分片,可以摆脱手动分片的管理困扰,集群自动切分数据做负载均衡。
MongoDB分片的基本思想就是将集合拆分成多个块,这些快分散在若干个片里,每个片只负责总数据的一部分,应用程序不必知道哪些片对应哪些数据,甚至不需要知道数据拆分了,所以在分片之前会运行一个路由进程,mongos进程,这个路由器知道所有的数据存放位置,应用只需要直接与mongos交互即可。mongos自动将请求转到相应的片上获取数据,从应用角度看分不分片没有什么区别。
2.2 架构
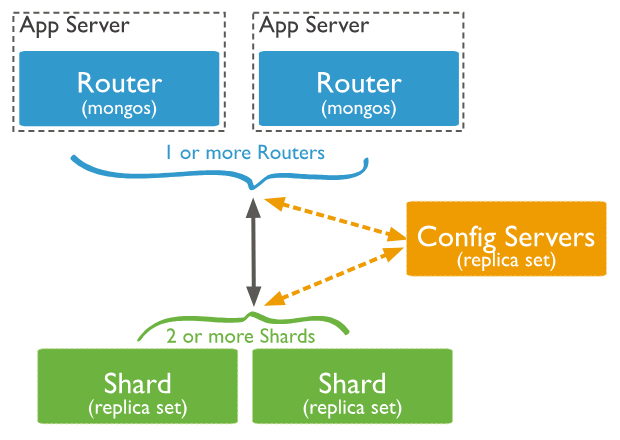
- Shard: 用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
- Config Server:mongod实例,存储了整个 ClusterMetadata
- Query Routers: 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用
- Shard Key: 片键,设置分片时需要在集合中选一个键,用该键的值作为拆分数据的依据,这个片键称之为(shard key),片键的选取很重要,片键的选取决定了数据散列是否均匀
2.3 分片集群搭建
下面是原生安装集群,docker安装可以参考:Docker部署MongoDB分片+副本集集群(实战)
1 | # 1.集群规划 |
启动6个 shard服务
1 | ## 启动 s0、r0 |
启动3个config服务
1 | ./mongod --port 27023 --dbpath /data/mongodb/shard/config1 --bind_ip 0.0.0.0 --replSet config/[123.57.80.91:27024,123.57.80.91:27025] --configsvr --fork --logpath /data/mongodb/shard/config1/config.log |
初始化 config server 副本集
1 | # 登录任意节点 congfig server |
启动 mongos 路由服务
1 | ./mongos --port 27026 --configdb config/123.57.80.91:27023,123.57.80.91:27024,123.57.80.91:27025 --bind_ip 0.0.0.0 --fork --logpath /data/mongodb/shard/config/config.log |
登录 mongos 服务
1 | # 1.登录 |
测试
1 | # 1.登陆27026节点 |
六、数据备份与恢复
1、常规数据备份与恢复
1.1 备份 MongoDB 数据库(包括身份验证)
假设我们要备份一个名为 mydatabase 的 MongoDB 数据库,并将备份文件保存在 /backup 目录下。数据库的用户名是 myuser,密码是 mypassword,身份验证数据库是 admin
1 | mongodump --host localhost --port 27017 --db mydatabase --username myuser --password mypassword --authenticationDatabase admin --out /backup |
<hostname>: MongoDB 主机名或 IP 地址<port>: MongoDB 端口,默认为 27017<database_name>: 要备份的数据库名称<username>: 用户名<password>: 用户密码<auth_db>: 用户的身份验证数据库/backup: 备份文件输出目录
1.2 恢复 MongoDB 数据库(包括身份验证)
假设我们要从之前的备份文件恢复 mydatabase 数据库
1 | mongorestore --host localhost --port 27017 --db mydatabase --username myuser --password mypassword --authenticationDatabase admin /backup/mydatabase |
<hostname>: MongoDB 主机名或 IP 地址<port>: MongoDB 端口,默认为 27017<database_name>: 要恢复的数据库名称<username>: 用户名<password>: 用户密码<auth_db>: 用户的身份验证数据库/backup/<database_name>: 备份文件所在的目录
最后,基于docker的可以参考:基于docker的mongodump / mongorestore 备份恢复

