
Kafka3学习笔记
一、Kafka概述和入门
1、Kafka概述
1.1 定义
Kafka是 一个开源的 分布式事件流平台 (Event StreamingPlatform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用。发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
1.2 消息队列
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。消息队列的两种模式:
- 点对点模式,消费者主动拉取数据,消息收到后清除消息
- 发布/订阅模式,可以有多个topic主题(浏览、点赞、收藏、评论等);消费者消费数据之后,不删除数据;每个消费者相互独立,都可以消费到数据
1.3 Kafka 基础架构
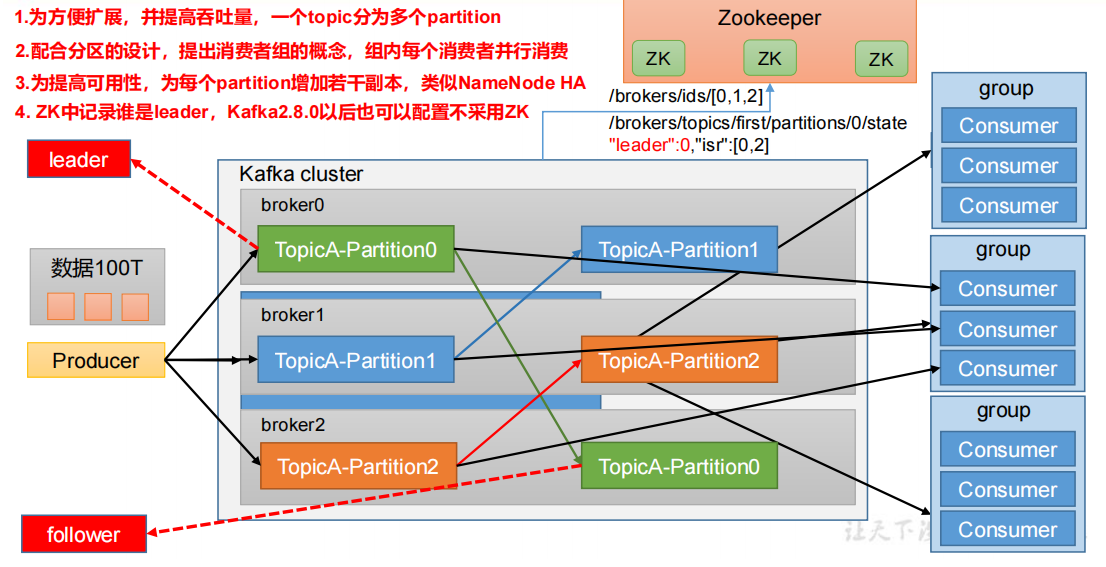
- **Producer:**消息生产者,就是向 Kafka broker 发消息的客户端
- **Consumer:**消息消费者,向Kafka broker 取消息的客户端
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
- **Broker:**一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic
- **Topic:**可以理解为一个队列,生产者和消费者面向的都是一个 topic
- **Partition:**为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个partition 是一个有序的队列
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower
- **Leader:**每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader
- **Follower:**每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个Follower 会成为新的Leader
2、Kafka 快速入门
2.1 安装部署
1 | # 实验配置环境是三台机器分别是hadoop102,103和104,每台机器需要安装zk和kafka,zk和xsync脚本参考之前笔记 |
2.2 集群启停脚本
在/home/atguigu/bin 目录下创建文件 kf.sh 脚本文件
1 |
|
1 | # 添加执行权限 |
3、Kafka 命令行操作
3.1 Topic命令行操作
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号,可以多个 |
| –topic <String: topic> | 操作的 topic 名称 |
| –create | 创建主题 |
| –delete | 删除主题 |
| –alter | 修改主题 |
| –list | 查看所有主题 |
| –describe | 查看主题详细描述 |
| –partitions <Integer: # of partitions> | 设置分区数 |
| –replication-factor<Integer: replication factor> | 设置分区副本 |
| –config <String: name=value> | 更新系统默认的配置 |
1 | bin/kafka-topics.sh |
3.2 生产者命令行操作
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号 |
| –topic <String: topic> | 操作的 topic 名称 |
1 | bin/kafka-console-producer.sh |
3.3 消费者命令行操作
| 参数 | 描述 |
|---|---|
| –bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号 |
| –topic <String: topic> | 操作的 topic 名称 |
| –from-beginning | 从头开始消费 |
| –group <String: consumer group id> | 指定消费者组名称 |
1 | bin/kafka-console-consumer.sh |
二、Kafka核心概念详解
中文文档:https://kafka.apachecn.org/documentation.html
kafka参数参考:Kafka配置参数详解
1、Kafka 生产者
1.1 生产者消息发送流程
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker
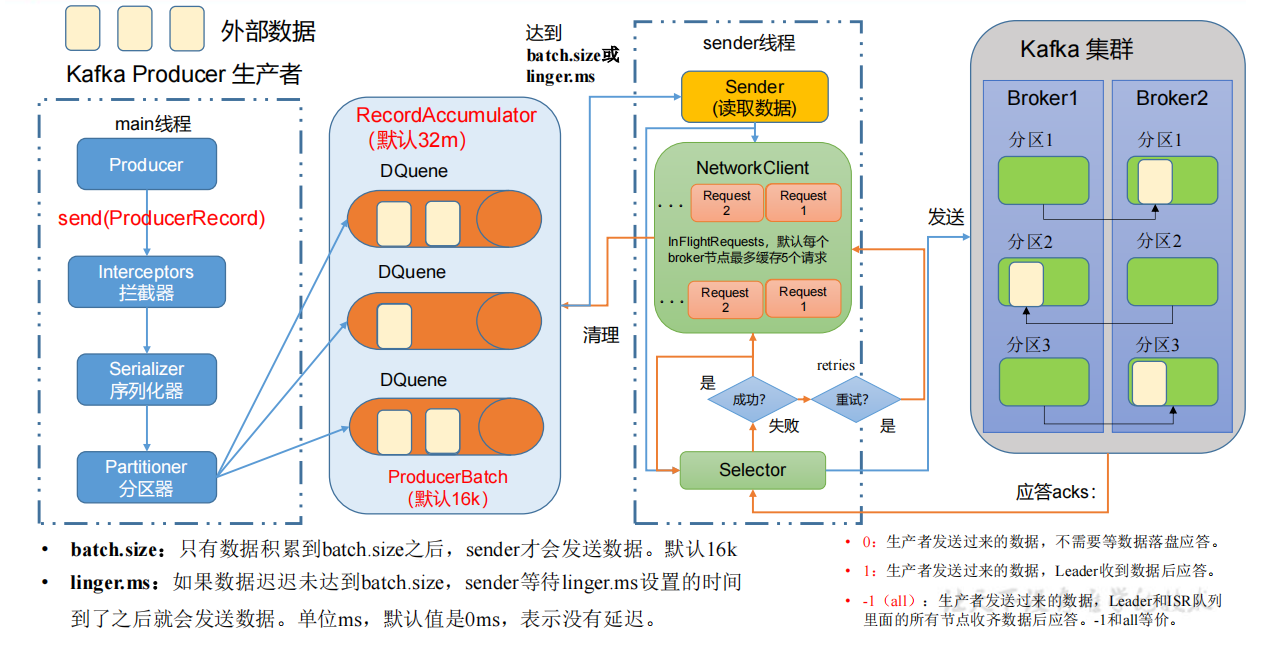
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 生产者连接集群所需的 broker 地址清单。 例如 hadoop102:9092,hadoop103:9092,hadoop104:9092,可以设置 1 个或者多个,中间用逗号隔开。注意这里并非需要所有的 broker 地址,因为生产者从给定的 broker里查找到其他 broker 信息。 |
| key.serializer 和 value.serializer | 指定发送消息的 key 和 value 的序列化类型。一定要写全类名 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列里面的所有节点收齐数据后应答。默认值是-1,-1 和all 是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性要保证该值是 1-5 的数字 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries 表示重试次数。默认是 int 最大值,2147483647。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是 100ms |
| enable.idempotence | 是否开启幂等性,默认 true,开启幂等性 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也就是不压缩。支持压缩类型:none、gzip、snappy、lz4 和 zstd |
1.2 Kafka操作 API
首先导入依赖
1 | <dependency> |
普通异步发送
1 | public static void main(String[] args) { |
带回调函数的异步发送
1 | /** |
同步发送 API
1 | // 未处理前会阻塞 |
1.3 生产者分区
分区便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据

自定义分区器
1 | public class MyPartitioner implements Partitioner { |
1.4 提高吞吐量
1 | //批次大小和等待时间二者只要有一个满足就会发送 |
1.5 数据可靠性
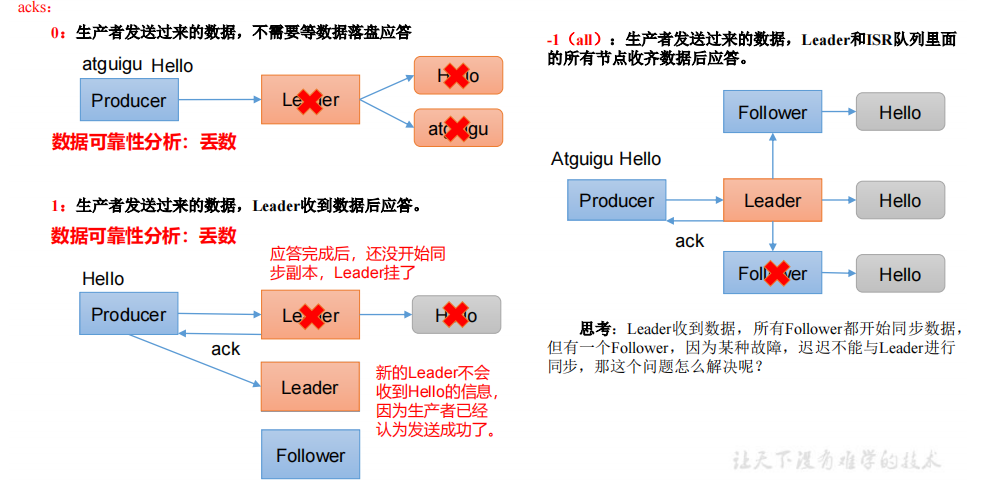
当ack=-1时,Leader维护了一个动态的in-sync replica set(ISR),意为和Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认30s。例如2超时,(leader:0, isr:0,1)。
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
可靠性总结:
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低;
- 在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。但是acks=-1时,有重复消费的可能
1 | // 设置 acks |
1.6 数据去重
- 至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
- 最多一次(At Most Once)= ACK级别设置为0
- 总结:
- At Least Once可以保证数据不丢失,但是不能保证数据不重复;
- At Most Once可以保证数据不重复,但是不能保证数据不丢失
- 精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条(必须按照顺序进行落盘),保证了不重复。重复数据的判断标准:具有**<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的**。所以幂等性只能保证的是在单分区单会话内不重复。开启幂等性:开启参数 enable.idempotence 默认为 true,false 关闭
事务原理
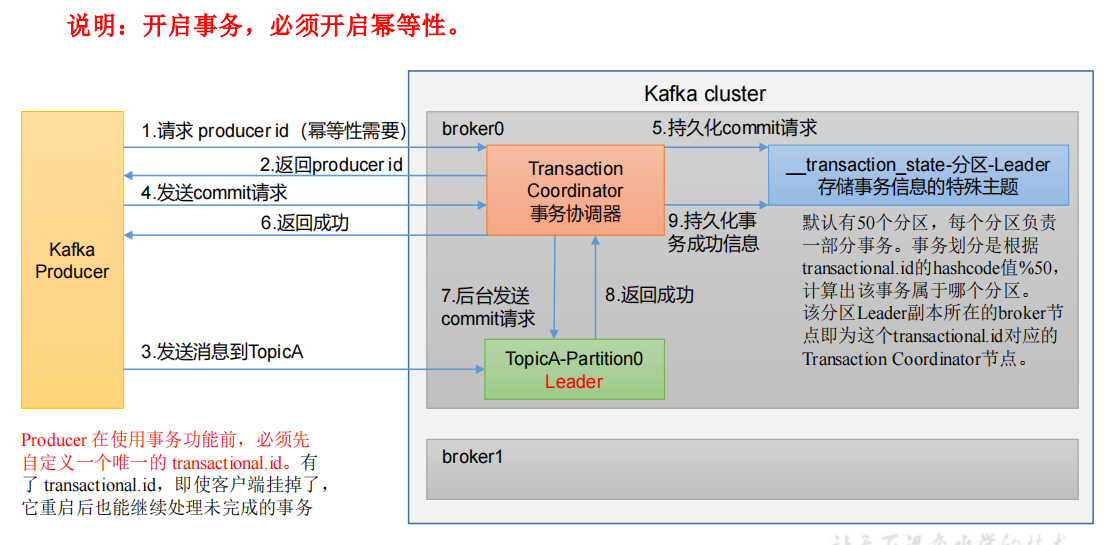
1 | // 共5个API |
1.7 数据顺序
对于单分区来说,数据是必定有序的;多分区,分区与分区间无序

2、Kafka Broker
2.1 Kafka Broker 工作流程
bin/zkCli.sh查看zookeeper里面的文件,也可以下载PrettyZoo(推荐)可视化软件查看Zookeeper 存储的 Kafka 信息
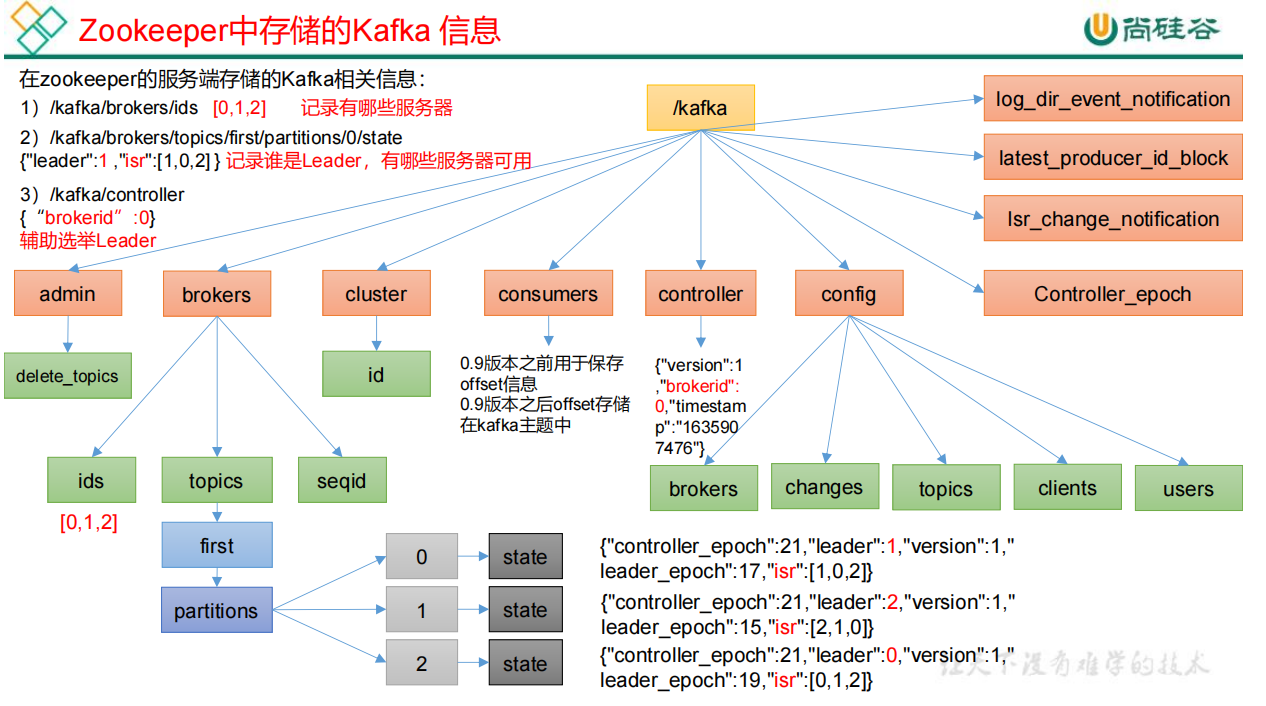
Kafka Broker 总体工作流程
1 | # 查看/kafka/brokers/ids 路径上的节点,首先进入了zk客户端 |
Broker 重要参数
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。 |
| auto.leader.rebalance.enable | 默认是 true。 自动Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G。 |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50% |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50%的 1/3 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理 |
2.2 节点服役和退役
服役新节点
1 | # 首先配置好一台新的机器,例如hadoop105 |
退役旧节点
1 | # 先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡 |
2.3 Kafka 副本基本信息
- Kafka 副本作用:提高数据可靠性
- Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率
- Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往Leader,然后 Follower 找 Leader 进行同步数据
- Kafka 分区中的所有副本统称为 AR(Assigned Repllicas),AR = ISR + OSR
- ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader
- OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
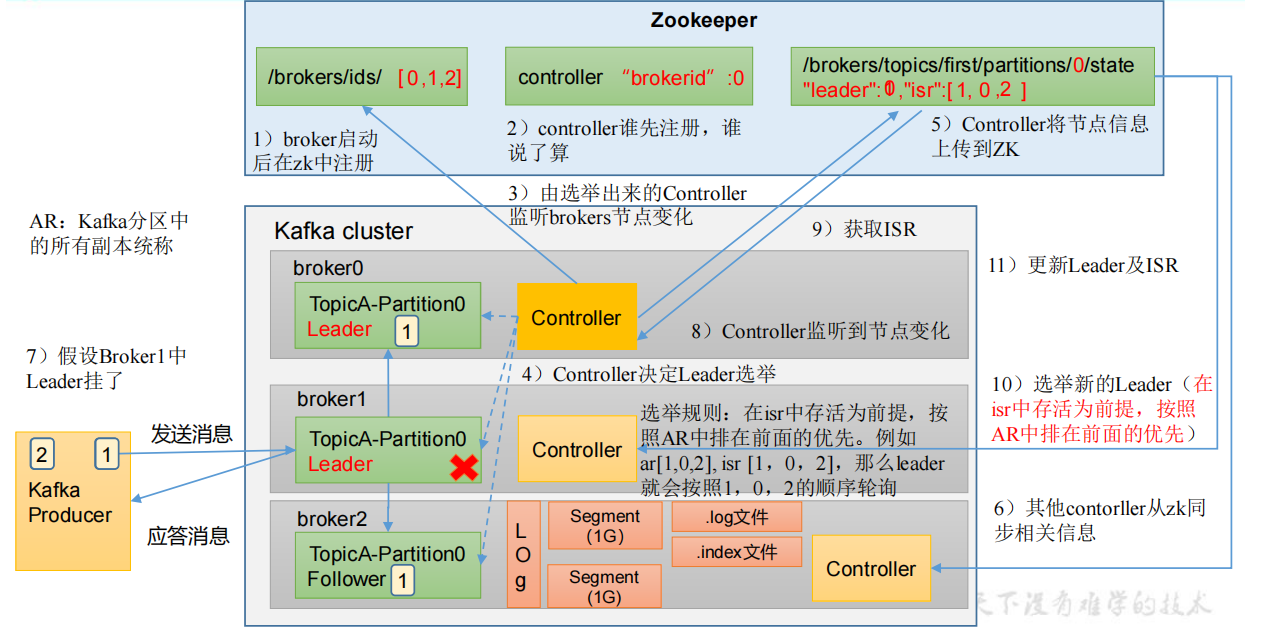
Leader 选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。Controller 的信息同步工作是依赖于 Zookeeper 的。
1 | # 创建一个新的 topic,4 个分区,4 个副本 |
2.4 Leader 和 Follower 故障处理细节

2.5 分区副本分配与负载平衡
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大(尽最大可能均匀分配分区)。所有需要手动调整分区副本的存储
1 | # 创建一个新的topic,4个分区,两个副本,名称为three。将 该topic的所有副本都存储到broker0和broker1两台服务器上 |

| 参数名称 | 描述 |
|---|---|
| auto.leader.rebalance.enable | 默认是 true。 自动Leader Partition 平衡。生产环境中,leader 重选举的代价比较大,可能会带来性能影响,建议设置为 false 关闭。 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间 |
**增加副本因子,**在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行
1 | bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 3 --replication-factor 1 --topic four |
2.6 文件存储
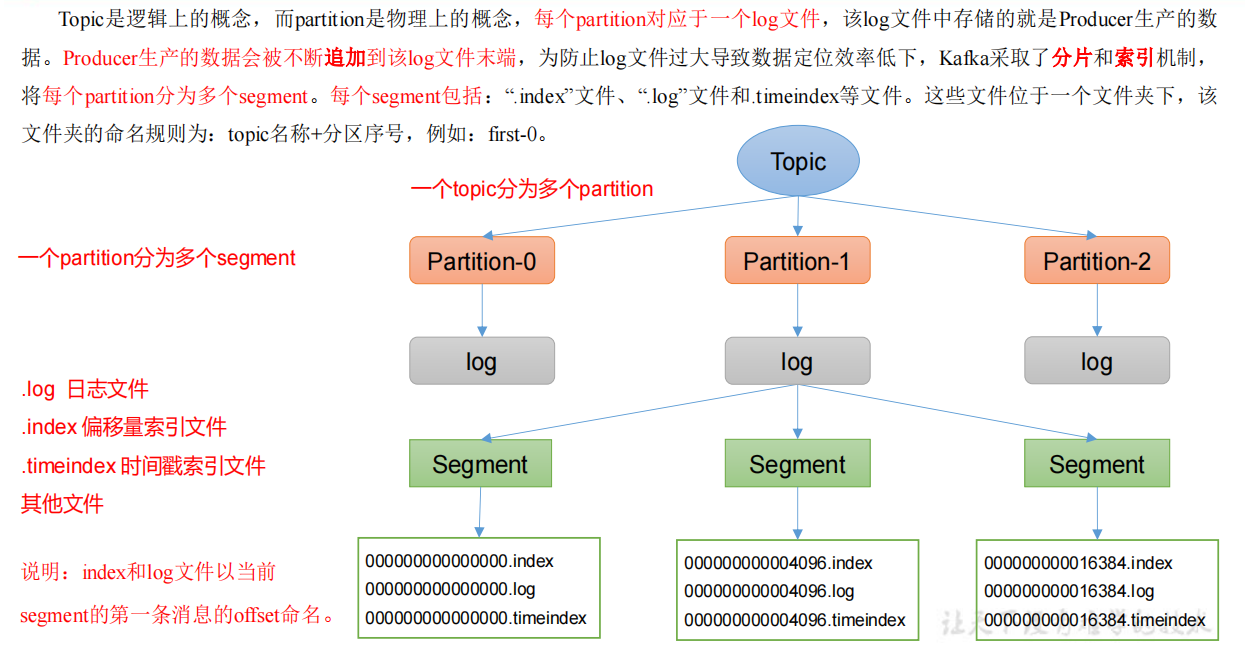
1 | # 思考:Topic 数据到底存储在什么位置 |
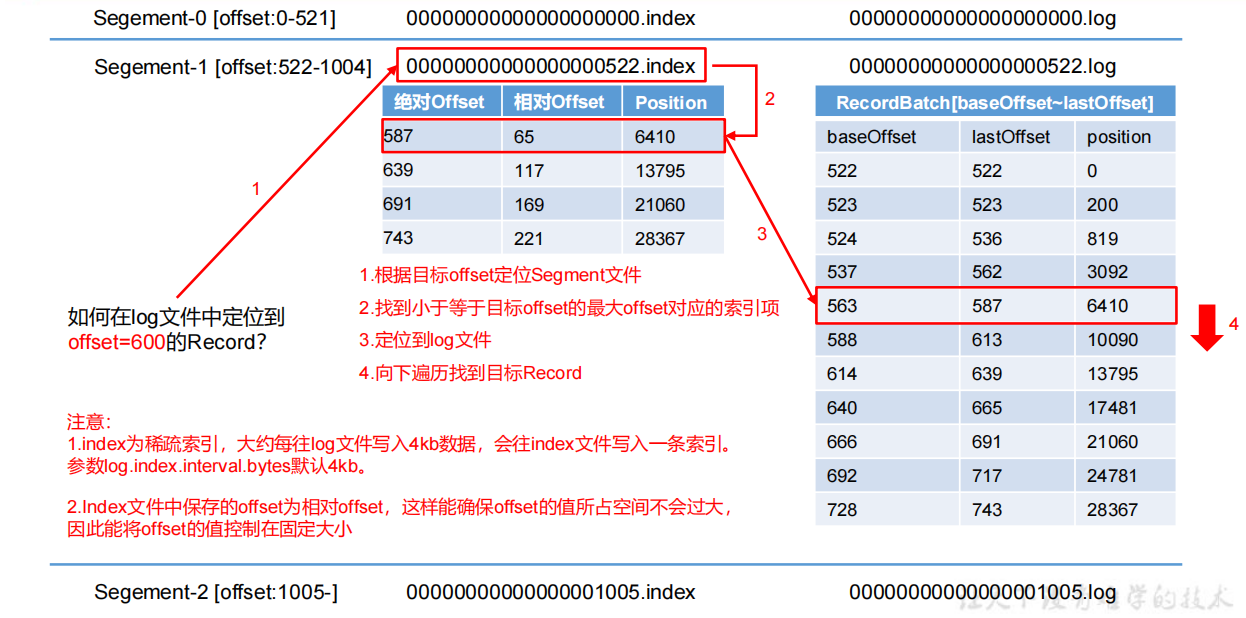
文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间
- log.retention.hours,最低优先级小时,默认 7 天
- log.retention.minutes,分钟
- log.retention.ms,最高优先级毫秒
- log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟
那么日志一旦超过了设置的时间,怎么处理呢?Kafka 中提供的日志清理策略有 delete 和 compact 两种
- delete 日志删除:将过期数据删除。log.cleanup.policy = delete 所有数据启用删除策略
- 基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳
- 基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。log.retention.bytes,默认等于-1,表示无穷大
- compact 日志压缩:**对于相同key的不同value值,只保留最后一个版本,**log.cleanup.policy = compact 所有数据启用压缩策略
- 压缩后的offset可能是不连续的,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费
- 这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料
2.7 高效读写数据(💥)
-
Kafka 本身是分布式集群,可以采用分区技术,并行度高
-
读数据采用稀疏索引,可以快速定位要消费的数据
-
顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间
-
页缓存 + 零拷贝技术
- 零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高
- PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用
| 参数 | 描述 |
|---|---|
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数, 默认是long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
2.8 自动创建主题
如果 broker 端配置参数 auto.create.topics.enable 设置为 true(默认值是 true),那么当生产者向一个未创建的主题发送消息时,会自动创建一个分区数为 num.partitions(默认值为1)、副本因子为 default.replication.factor(默认值为 1)的主题。除此之外,当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会自动创建一个相应主题。这种创建主题的方式是非预期的,增加了主题管理和维护的难度。
生产环境建议将该参数设置为 false。
3、Kafka 消费者(重点)
3.1 Kafka 消费方式
-
pull(拉)模 式
consumer采用从broker中主动拉取数据。Kafka采用这种方式
-
push(推)模式
Kafka没有采用这种方式,因为由broker 决定消息发送速率,很难适应所有消费者的消费速率。例如推送的速度是50m/s, Consumer1、Consumer2就来不及处理消息。pull模式不足之处是,如果Kafka没有数据,消费者可能会陷入循环中,一直返回空数据
3.2 Kafka 消费者工作流程
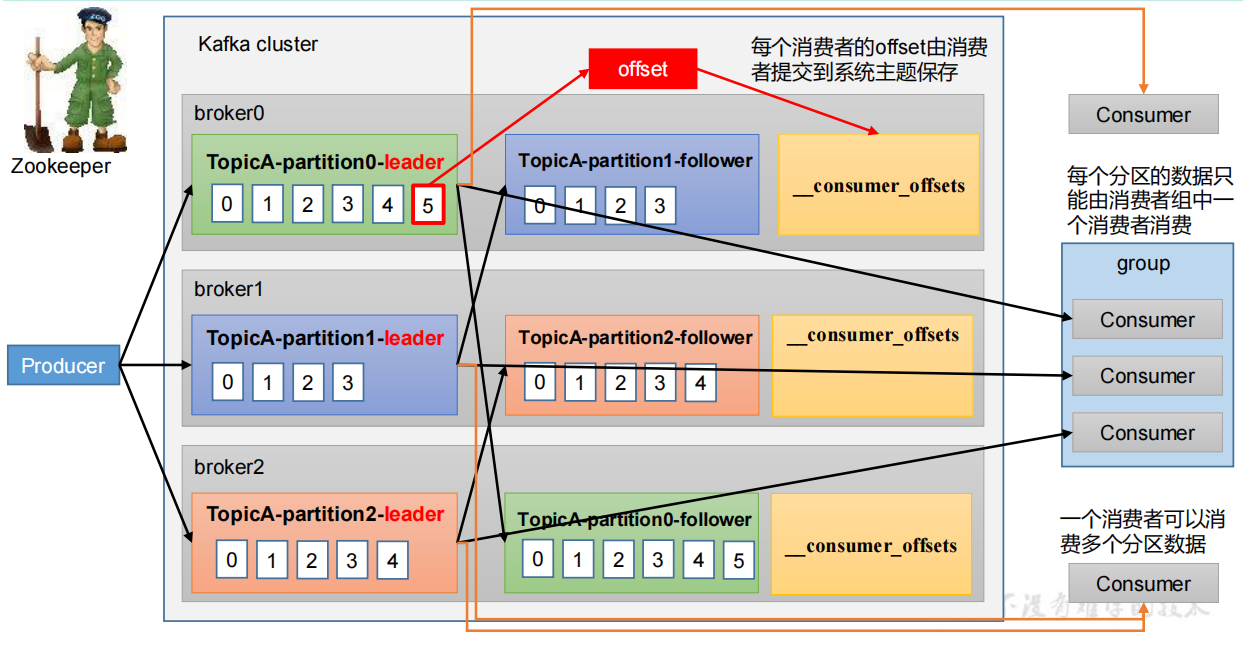
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
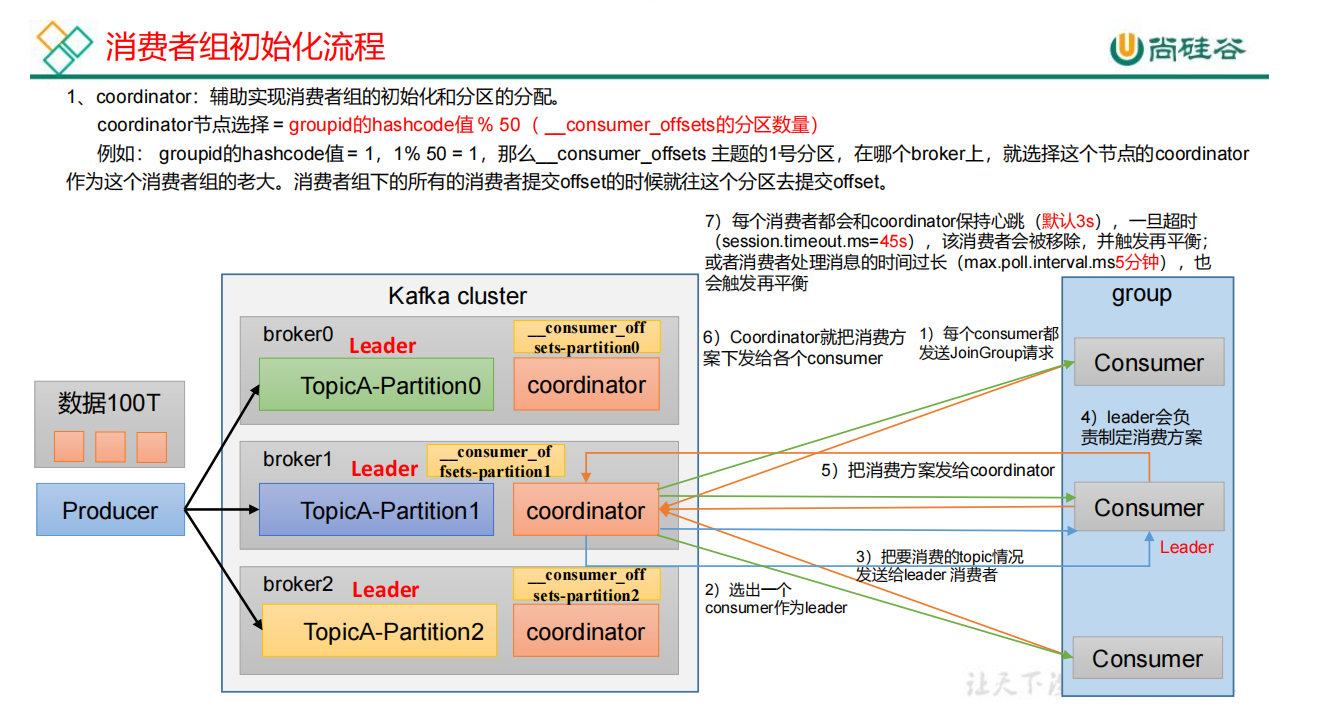
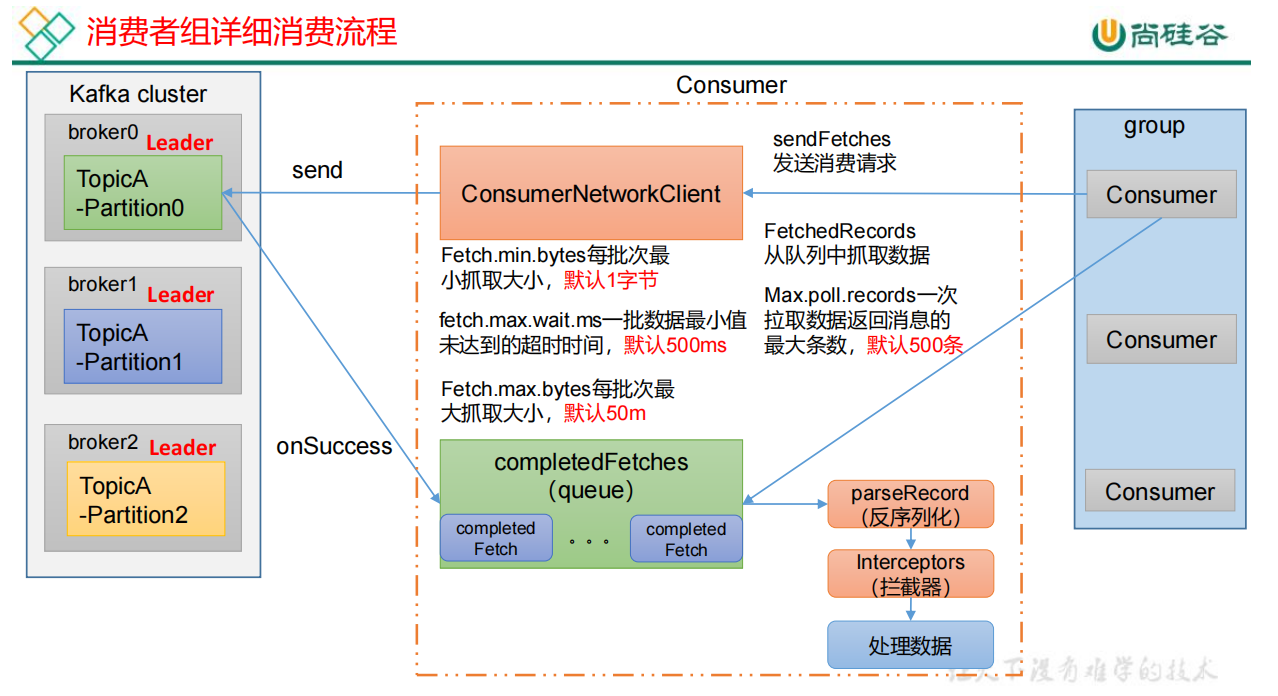
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 向 Kafka 集群建立初始连接用到的 host/port 列表 |
| key.deserializer 和value.deserializer | 指定接收消息的 key 和 value 的反序列化类型。一定要写全类名 |
| group.id | 标记消费者所属的消费者组 |
| enable.auto.commit | 默认值为 true,消费者会自动周期性地向服务器提交偏移量 |
| auto.commit.interval.ms | 如果设置了 enable.auto.commit 的值为 true, 则该值定义了消费者偏移量向Kafka 提交的频率,默认 5s |
| auto.offset.reset | 当 Kafka 中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:自动重置偏移量到最早的偏移量。 latest:默认,自动重置偏移量为最新的偏移量。 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常。 anything:向消费者抛异常。 |
| offsets.topic.num.partitions | consumer_offsets 的分区数,默认是 50 个分区。 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms , 也不应该高于session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes ( broker config)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条。 |
3.3 消费者API
1 | public static void main(String[] args) { |
3.4 分区的分配以及再平衡
| 参数名称 | 描述 |
|---|---|
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间,默认 3s。该条目的值必须小于 session.timeout.ms , 也不应该高于session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间,默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是 5 分钟。超过该值,该消费者被移除,消费者组执行再平衡。 |
| partition.assignment.strategy | 消 费 者 分 区 分 配 策 略 , 默 认 策 略 是 Range +CooperativeSticky。Kafka 可以同时使用多个分区分配策略。可以选择的策略包括: Range 、 RoundRobin 、 Sticky 、CooperativeSticky |
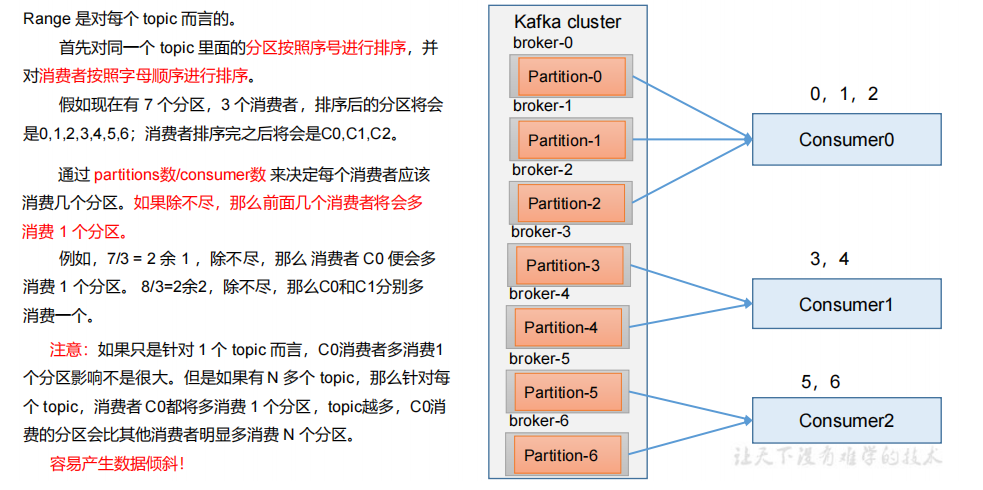
** Range 以及再平衡**
RoundRobin 以及再平衡
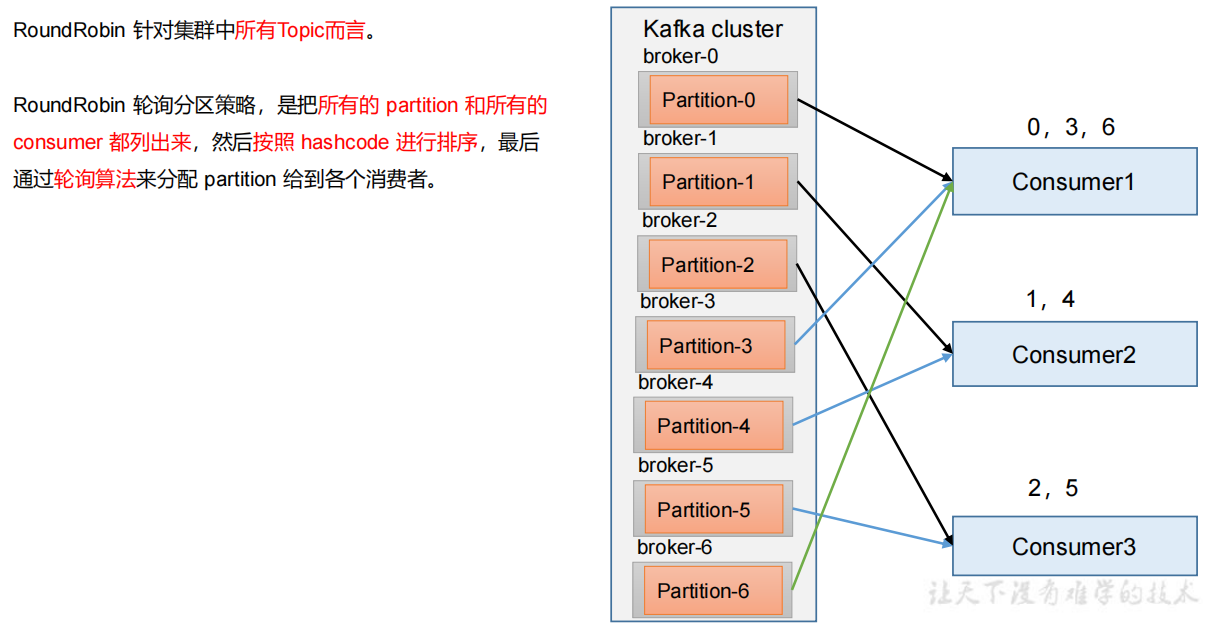
Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化(第一次分配会随机)
1 | // org.apache.kafka.clients.consumer.RoundRobinAssignor |
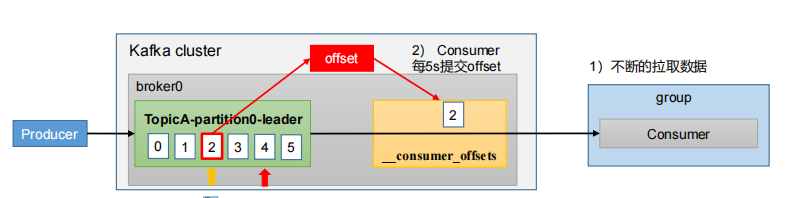
3.5 offset 位移
从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。__consumer_offsets 主题里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行compact,也就是每个 group.id+topic+分区号就保留最新数据
1 | # 在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false |
自动提交 offset
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。自动提交offset的相关参数:
- enable.auto.commit:是否开启自动提交offset功能,默认是true
- auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
1 | // 自动提交 |
手动提交 offset
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故有可能提交失败
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据
1 | public static void main(String[] args) { |
3.6 offset其他情况
auto.offset.reset = earliest | latest | none 默认是 latest。当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
- earliest:自动将偏移量重置为最早的偏移量,–from-beginning
- latest(默认值):自动将偏移量重置为最新偏移量
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常
- 任意指定 offset 位移开始消费
1 | // 指定位置进行消费 |
指定时间消费
在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。例如要求按照时间消费前一天的数据,怎么处理
1 | public static void main(String[] args) { |
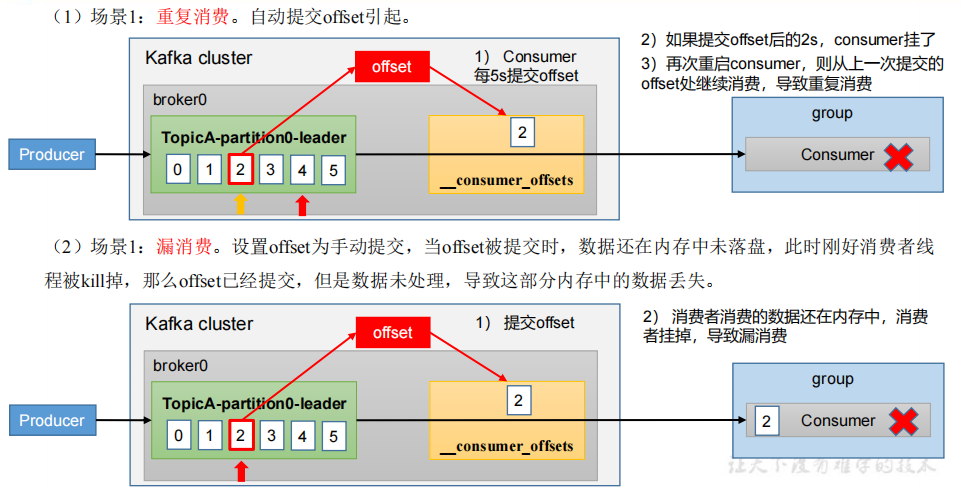
漏消费和重复消费
3.7 消费者事务
如果想完成Consumer端的精准一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将Kafka的offset保存到支持事务的自定义介质(比 如MySQL)
3.8 数据积压(消费者如何提高吞吐量)
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数。(两者缺一不可)
- 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压
| 参数名称 | 描述 |
|---|---|
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (brokerconfig)or max.message.bytes (topic config)影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数,默认是 500 条 |
4、Kafka-Eagle 监控
4.1 概述与环境准备
Kafka-Eagle 框架可以监控 Kafka 集群的整体运行情况,在生产环境中经常使用。Kafka-Eagle 的安装依赖于 MySQL,MySQL 主要用来存储可视化展示的数据。Mysql安装可以参考之前hive的学习笔记
4.2 Kafka 环境准备
1 | # 关闭 Kafka 集群 |
4.3 Kafka-Eagle 安装
1 | wget https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz |
5、Kafka-Kraft 模式
5.1 Kafka-Kraft 架构
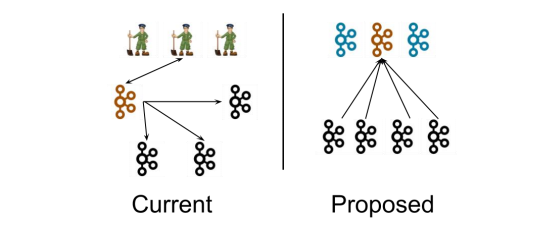
左图为 Kafka 现有架构,元数据在 zookeeper 中,运行时动态选举 controller,由controller 进行 Kafka 集群管理。右图为 kraft 模式架构(实验性),不再依赖zookeeper 集群,而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。这样做的好处有以下几个:
- Kafka 不再依赖外部框架,而是能够独立运行;
- controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
- 由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
- controller 不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策
5.2 Kafka-Kraft 集群部署
1 | # 再次解压一份 kafka 安装包 |
5.3 Kafka-Kraft 集群启动停止脚本
在/home/atguigu/bin 目录下创建文件 kf2.sh 脚本文件
1 |
|
1 | # 添加执行权限 |
6、Kafka配置文件说明
6.1 Server.properties配置文件说明
1 | #broker的全局唯一编号,不能重复 |
6.2 consumer消费者配置详细说明
1 | # zookeeper连接服务器地址 |
三、Kafka外部系统集成
1、集成 Flume
1.1 Flume生产者
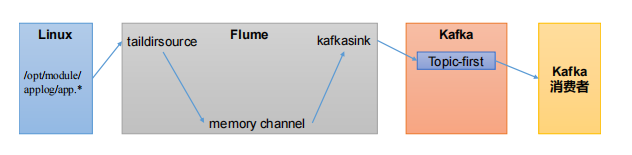
1 | # 启动 kafka 集群 |
1.2 Flume 消费者
1 | # 拉取kafka消息到控制台 |
2、集成 Flink
Flink 是一个在大数据开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于Flink 的消费者。首先创建maven项目
1 | <dependencies> |
将 log4j.properties 文件添加到 resources 里面,就能更改打印日志的级别为 error
1 | log4j.rootLogger=error, stdout,R |
在 java 文件夹下创建包名为 com.atguigu.flink,首先是测试flink生产者代码
1 | public static void main(String[] args) throws Exception { |
Flink 消费者
1 | public static void main(String[] args) throws Exception { |
3、集成 SpringBoot
首先是导入依赖
1 | <!-- spring-kafka --> |
3.1 简单Demo
添加lombok插件,spring-boot-starter-web依赖以及spring-kafka依赖。首先修改 SpringBoot 核心配置文件 application.propeties, 添加生产者相关信息
1 | # 应用名称 |
创建 controller 从浏览器接收数据, 并写入指定的 topic
1 |
|
SpringBoot 消费者
1 |
|
3.2 完整Demo
这次是yml配置文件
1 | # kafka 配置 |
创建消息生产者
1 |
|
创建消息消费者
1 |
|
发送测试
1 | (SpringRunner.class) |
4、集成 Spark
创建一个 maven 项目 spark-kafka,在项目 spark-kafka 上点击右键,Add Framework Support=》勾选 scala,在 main 下创建 scala 文件夹,并右键 Mark Directory as Sources Root=>在 scala 下创建包名为 com.atguigu.spark,添加配置文件
1 | <dependencies> |
将 log4j.properties 文件添加到 resources 里面,就能更改打印日志的级别为 error,见上面
Spark 生产者
1 | object SparkKafkaProducer { |
Spark 消费者,添加配置文件
1 | <dependencies> |
1 | object SparkKafkaConsumer { |
四、Kafka生产调优
1、Kafka 硬件配置选择
1.1 场景说明
- 100 万日活,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条
- 1 亿/24 小时/60 分/60 秒 = 1150 条/每秒钟
- 每条日志大小:0.5k - 2k(取 1k)
- 1150 条/每秒钟 * 1k ≈ 1m/s
- 高峰期每秒钟:1150 条 * 20 倍 = 23000 条
- 每秒多少数据量:20MB/s
1.2 服务器台数选择
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1= 2 * (20m/s * 2 / 100) + 1= 3 台
建议 3 台服务器
1.3 内存选择
Kafka 内存组成:堆内存 + 页缓存,Kafka 堆内存建议每个节点:10g ~ 15g,在 kafka-server-start.sh 中修改
1 | if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then |
查看kafka内存使用情况
1 | jps |
页缓存:页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中25%的数据在内存中就好。每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。例如 10 个分区,页缓存大小=(10 * 1g * 25%)/ 3 ≈ 1g,建议服务器内存大于等于 11G
1.4 其他硬件配置
磁盘选择
kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。建议选择普通的机械硬盘。每天总数据量:1 亿条 * 1k ≈ 100g,100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T,建议三台服务器硬盘总大小,大于等于 1T
CPU 选择
- num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%
- num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3
- num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3。建议 32 个 cpu core
网络选择
网络带宽 = 峰值吞吐量 ≈ 20MB/s 选择千兆网卡即可。100Mbps 单位是 bit;10M/s 单位是 byte ; 1byte = 8bit,100Mbps/8 = 12.5M/s。一般百兆的网卡(100Mbps )、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
2、生产者、Topic、消费者
具体的参数等详见第二章
3、Kafka 总体调优
3.1 提升吞吐量
- 生产者buffer.memory:发送消息的缓冲区大小,默认值是 32m,可以增加到 64m
- 生产batch.size:默认是 16k。如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;如果 batch 太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时
- 生产linger.ms,这个值默认是 0,意思就是消息必须立即被发送。一般设置一个 5-100毫秒。如果 linger.ms 设置的太小,会导致频繁网络请求,吞吐量下降;如果 linger.ms 太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时
- 生产compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销
- 增加topic分区
- 消费者调整 fetch.max.bytes 大小,默认是 50m;调整 max.poll.records 大小,默认是 500 条
- 增加下游消费者处理能力
3.2 数据精准一次
- 生产者角度acks 设置为-1 (acks=-1);幂等性(enable.idempotence = true) + 事务
- broker 服务端角度,分区副本大于等于 2 (–replication-factor 2),ISR 里应答的最小副本数量大于等于 2 (min.insync.replicas = 2)
- 消费者事务 + 手动提交 offset (enable.auto.commit = false);消费者输出的目的地必须支持事务(MySQL、Kafka)
3.3 合理设置分区数
创建一个只有 1 个分区的 topic。测试这个 topic 的 producer 吞吐量和 consumer 吞吐量。假设他们的值分别是 Tp 和 Tc,单位可以是 MB/s。然后假设总的目标吞吐量是 Tt,那么分区数 = Tt / min(Tp,Tc)
例如:producer 吞吐量 = 20m/s;consumer 吞吐量 = 50m/s,期望吞吐量 100m/s;分区数 = 100 / 20 = 5 分区,分区数一般设置为:3-10 个,分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
3.4 单条日志大于 1m
| 参数名称 | 描述 |
|---|---|
| message.max.bytes | 默认 1m,broker 端接收每个批次消息最大值 |
| max.request.size | 默认 1m,生产者发往 broker 每个请求消息最大值,针对 topic级别设置消息体的大小 |
| replica.fetch.max.bytes | 默认 1m,副本同步数据,每个批次消息最大值 |
| fetch.max.bytes | 默认Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此这不是一个绝对最大值。一批次的大小受message.max.bytes (broker config)or max.message.bytes (topic config)影响。 |
3.5 服务器宕机
- 先尝试重新启动一下,如果能启动正常,那直接解决
- 如果重启不行,考虑增加内存、增加 CPU、网络带宽
- 如果将 kafka 整个节点误删除,如果副本数大于等于 2,可以按照服役新节点的方式重新服役一个新节点,并执行负载均衡
4、集群压力测试
1 | # =============生产者压测============= |

