
Zookeeper3.5.7源码分析
Zookeeper3.5.7源码分析
一、Zookeeper算法一致性
1、Paxos 算法
1.1 概述
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。Paxos算法解决的问题:就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,都不会破坏整个系统的一致性。
在一个Paxos系统中,首先将所有节点划分为Proposer(提议者),Acceptor(接受者),和Learner(学习者)。(注意:每个节点都可以身兼数职),一个完整的Paxos算法流程分为三个阶段:
Prepare准备阶段
- Proposer向多个Acceptor发出Propose请求Promise(承诺)
- Acceptor针对收到的Propose请求进行Promise(承诺)
Accept接受阶段
- Proposer收到多数Acceptor承诺的Promise后,向Acceptor发出Propose请求
- Acceptor针对收到的Propose请求进行Accept处理
Learn学习阶段:Proposer将形成的决议发送给所有Learners
1.2 算法流程

1.3 算法缺陷
在网络复杂的情况下,一个应用 Paxos 算法的分布式系统,可能很久无法收敛,甚至陷入活锁的情况。造成这种情况的原因是系统中有一个以上的 Proposer,多个Proposers 相互争夺Acceptor,造成迟迟无法达成一致的情况。针对这种情况,一种改进的 Paxos 算法被提出:从系统中选出一个节点作为 Leader,只有 Leader 能够发起提案。这样,一次 Paxos 流程中只有一个Proposer,不会出现活锁的情况
2、ZAB 协议
2.1 概述
Zab 借鉴了 Paxos 算法,是特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper 设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader 客户端将数据同步到其他 Follower 节点。即 Zookeeper 只有一个 Leader 可以发起提案
2.2 Zab 协议内容
Zab 协议包括两种基本的模式:消息广播、崩溃恢复
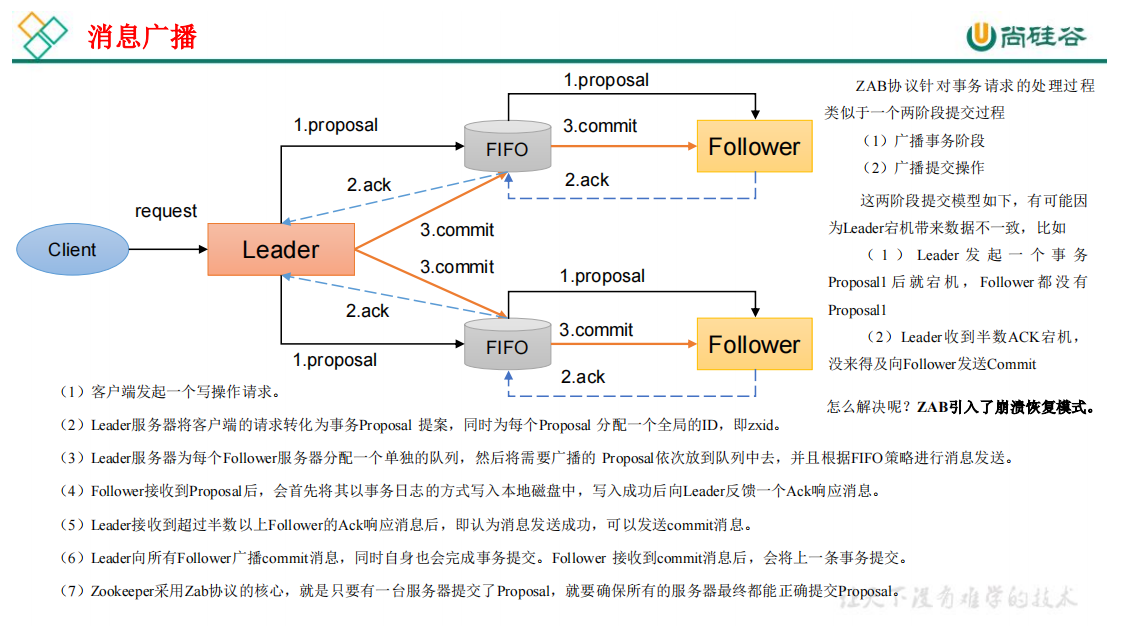
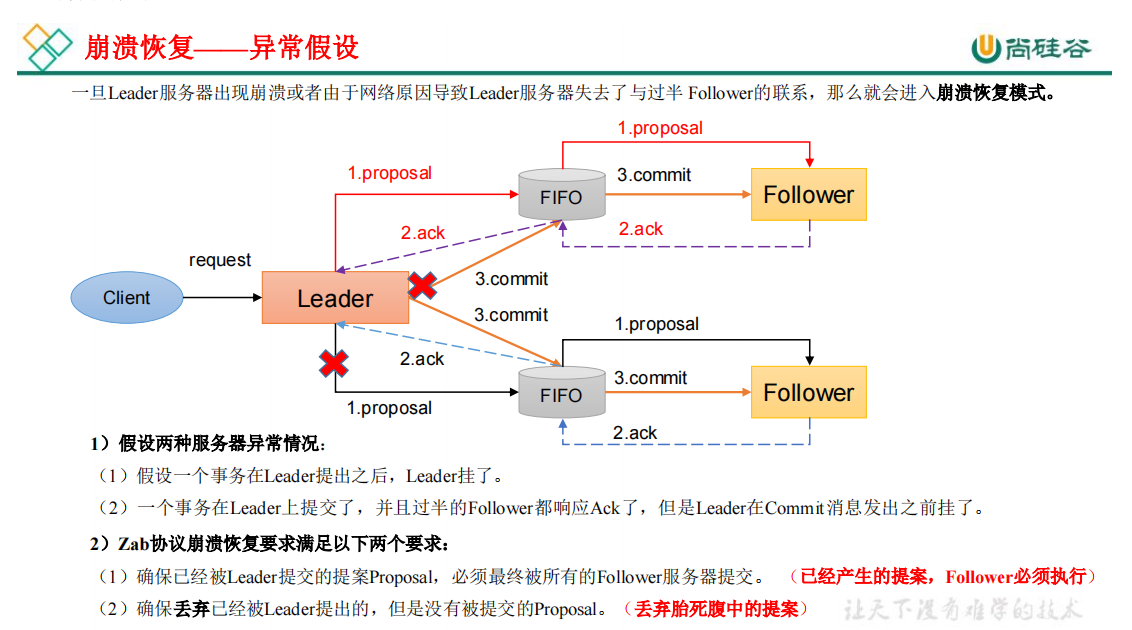
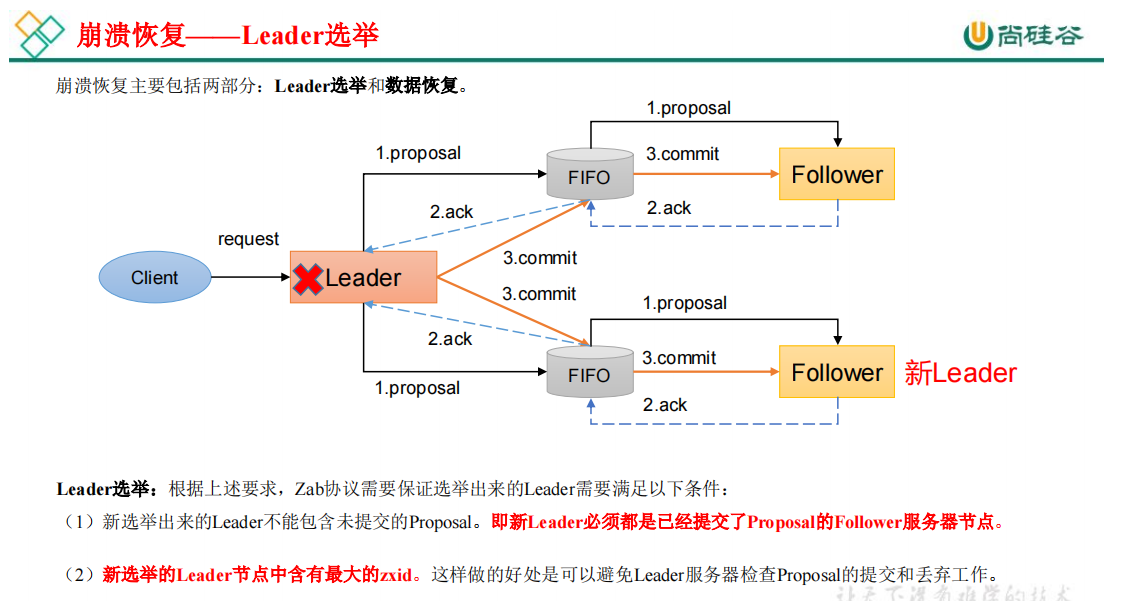
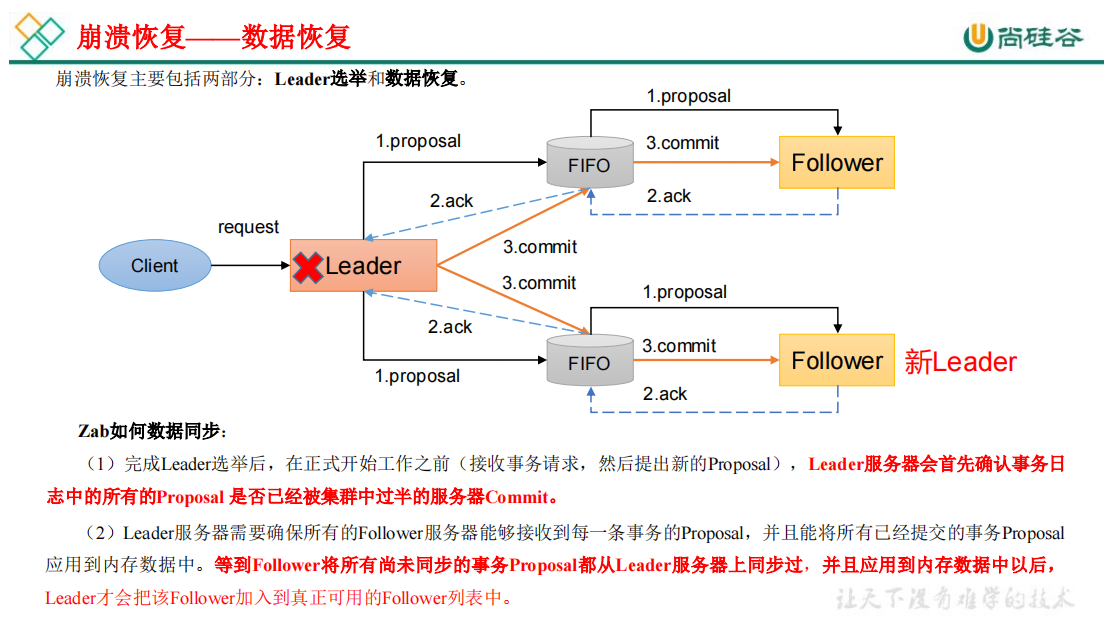
3、CAP理论
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种
-
一致性(C:Consistency)
在分布式环境中,一致性是指数据在多个副本之间是否能够保持数据一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
-
可用性(A:Available)
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果
-
分区容错性(P:Partition Tolerance)
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障
这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。ZooKeeper保证的是CP
- ZooKeeper不能保证每次服务请求的可用性。(注:在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
- 进行Leader选举时集群都是不可用
二、源码详解
Zookeeper源码下载地址:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
1、辅助源码
1.1 持久化源码(了解)
Leader 和 Follower 中的数据会在内存和磁盘中各保存一份。所以需要将内存中的数据持久化到磁盘中,在 org.apache.zookeeper.server.persistence 包下的相关类都是序列化相关的代码

1 | public interface SnapShot { |
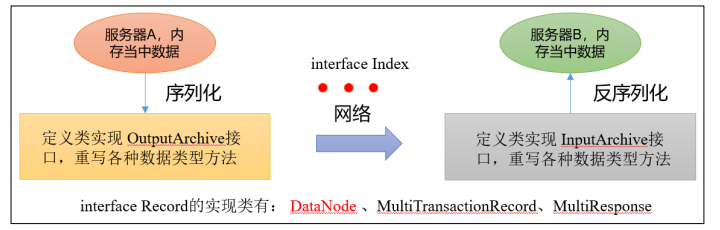
1.2 序列化源码
zookeeper-jute 代码是关于Zookeeper 序列化相关源码
2、ZK 服务端初始化源码解析
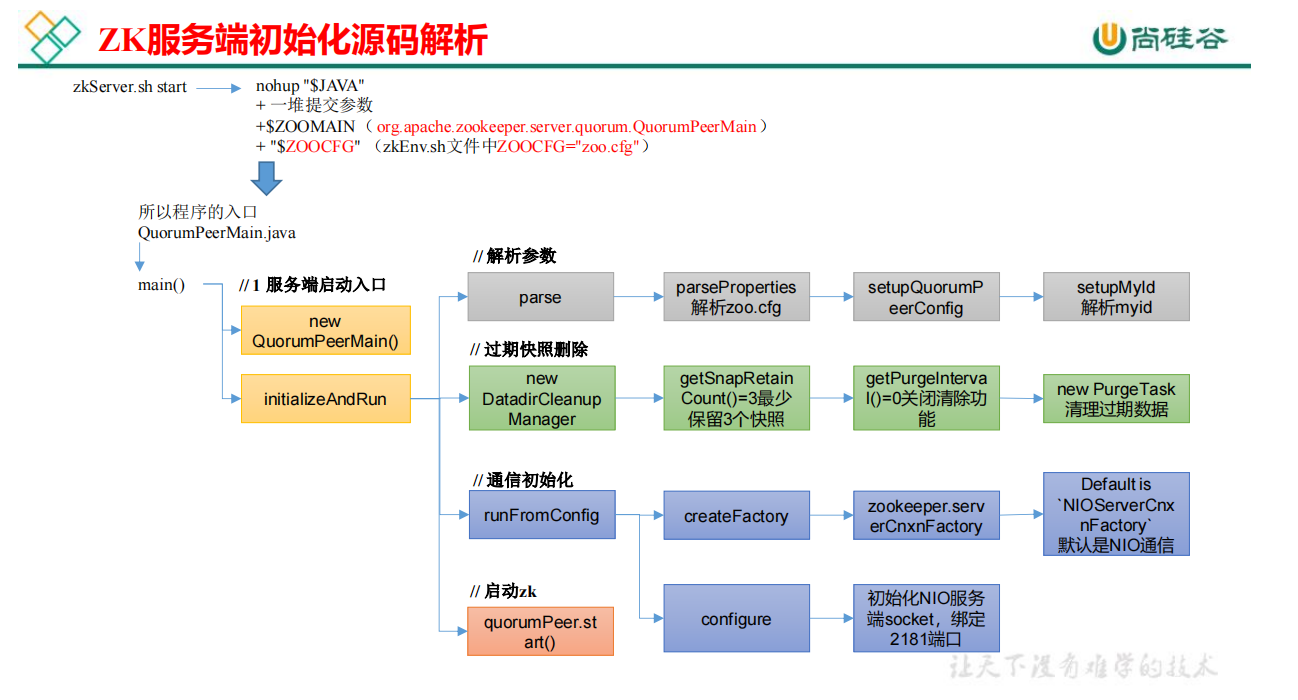
2.1 启用脚本分析
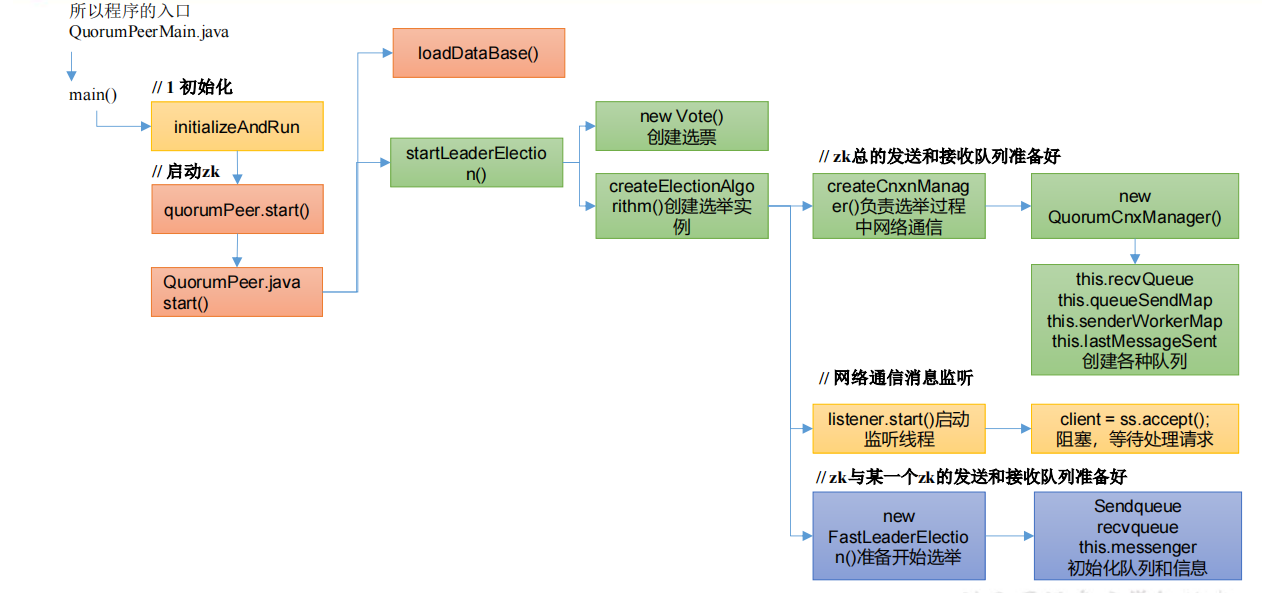
zkServer.sh start 底层的实际执行内容,所以程序的入口是 QuorumPeerMain.java 类
1 | nohup "$JAVA" |
2.2 ZK 服务端启动入口
源码里查找QuorumPeerMain类
1 | public static void main(String[] args) { |
2.3 解析参数 zoo.cfg 和 myid
1 | public void parse(String path) throws ConfigException { |
2.4 过期快照删除
可以启动定时任务,对过期的快照,执行删除。默认该功能时关闭的
1 | // 2 启动定时任务,对过期的快照,执行删除(默认是关闭) |
2.5 初始化通信组件
1 | if (args.length == 1 && config.isDistributed()) { |
初始化 NIO 服务端 Socket(并未启动),ctrl + alt +B 查找 configure 实现类,NIOServerCnxnFactory.java
1 |
|
3、ZK 服务端加载数据源码解析
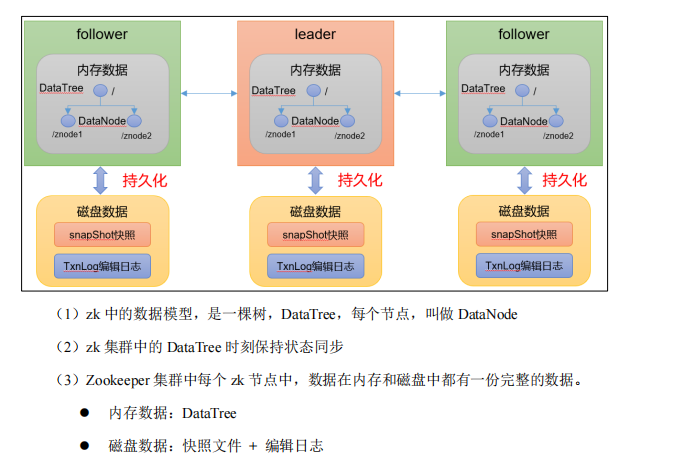
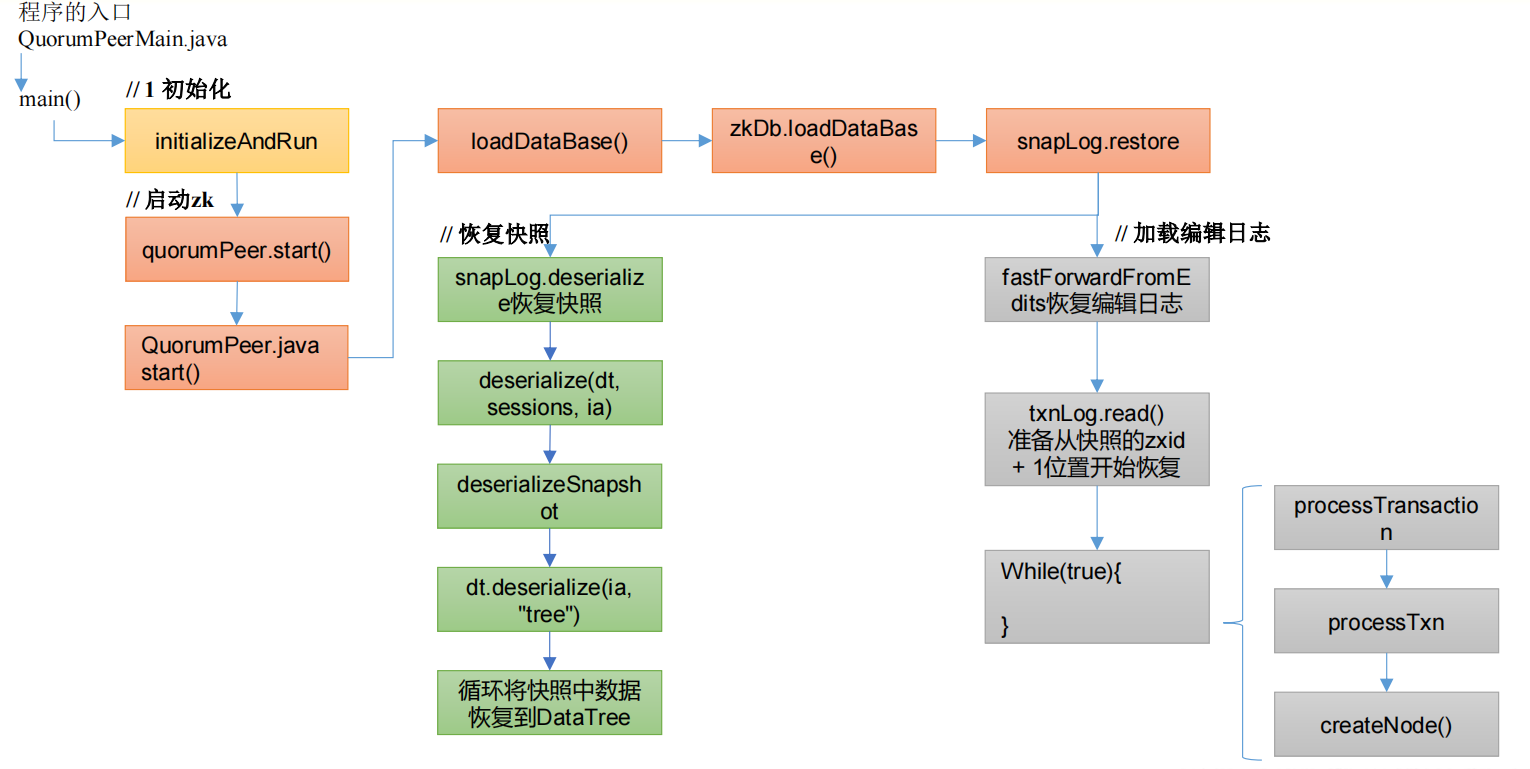
3.1 冷启动数据恢复快照数据
1 | public synchronized void start() { |
3.2 冷启动数据恢复编辑日志
回到 FileTxnSnapLog.java 类中的 restore 方法
1 | public long restore(DataTree dt, Map<Long, Integer> sessions,PlayBackListener listener) throws IOException { |
4、ZK 选举源码解析
选举流程可以参考之前的zookeeper基础学习
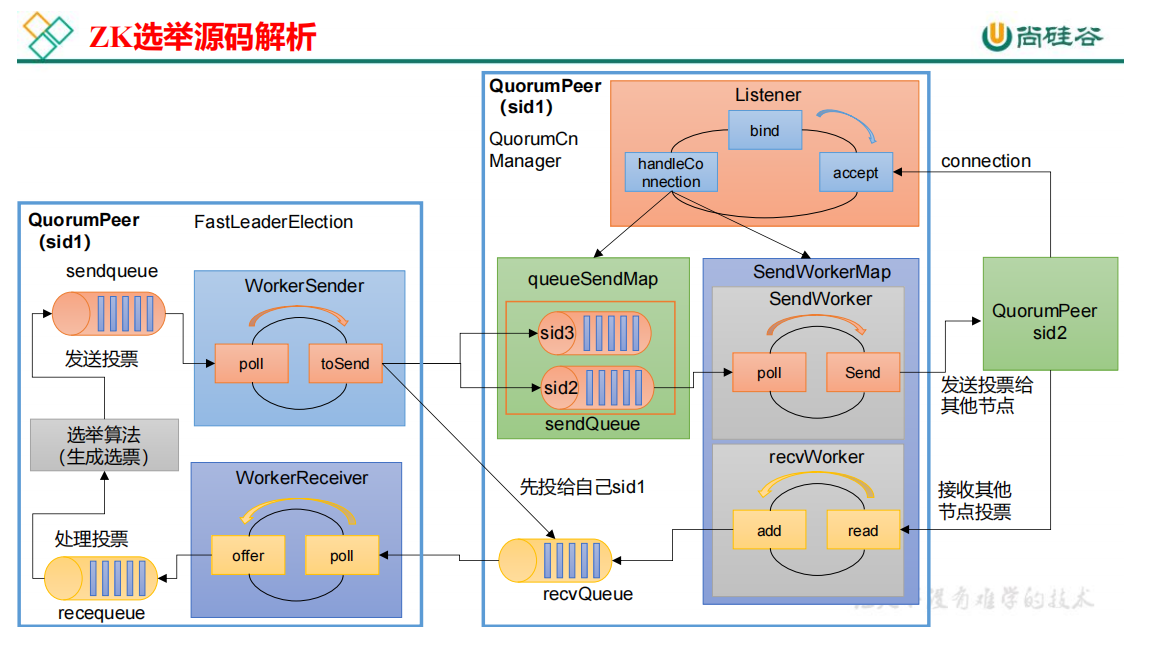
4.1 选举准备
1 |
|
监听线程初始化,点击 QuorumCnxManager.Listener,找到对应的 run 方法
1 |
|
选举准备,点击 FastLeaderElection
1 | public FastLeaderElection(QuorumPeer self, QuorumCnxManager manager){ this.stop = false; |
4.2 选举执行
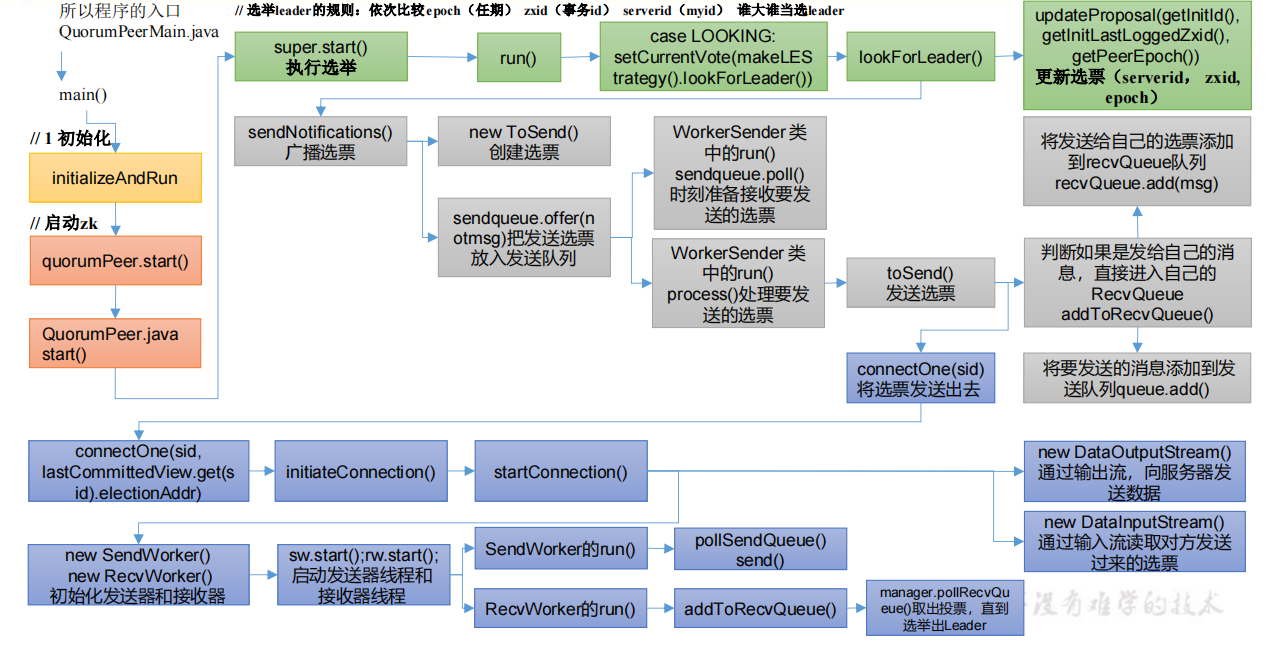
QuorumPeer.java中执行 super.start();就相当于执行 QuorumPeer.java 类中的 run()方法。当 Zookeeper 启动后,首先都是 Looking 状态,通过选举,让其中一台服务器成为 Leader,其他的服务器成为 Follower。
1 |
|
ctrl+alt+b 点击 lookForLeader()的实现类 FastLeaderElection.java
1 | public Vote lookForLeader() throws InterruptedException { |
点击 sendNotifications,广播选票,把自己的选票发给其他服务器
1 | private void sendNotifications() { |
在 FastLeaderElection.java 类中查找 WorkerSender 线程
1 | class WorkerSender extends ZooKeeperThread { |
与要发送的服务器节点建立通信连接,创建并启动发送器线程和接收器线程
1 | //connectOne->connectOne->initiateConnection->startConnection |
点击 SendWorker,并查找该类下的 run 方法;点击 RecvWorker,并查找该类下的 run 方法(这里不举例了),在 FastLeaderElection.java 类中查找 WorkerReceiver 线程
1 | public void run() { |
5、Follower 和 Leader 状态同步源码
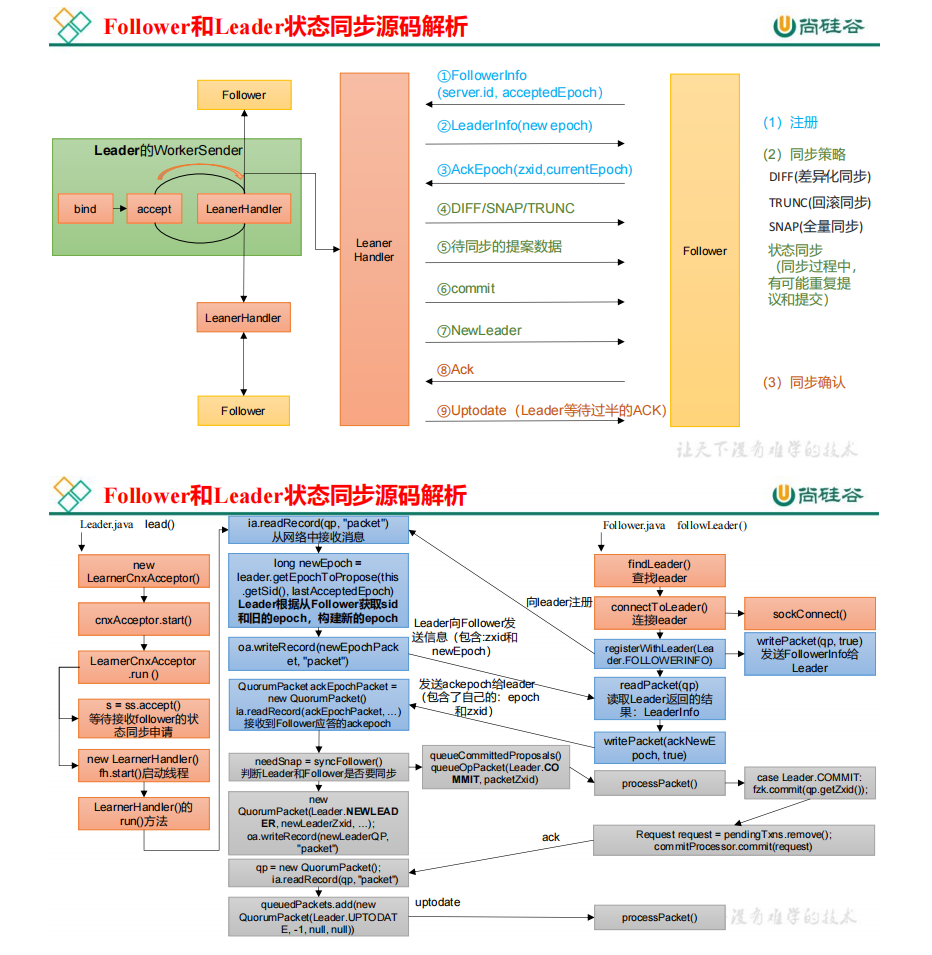
当选举结束后,每个节点都需要根据自己的角色更新自己的状态。选举出的 Leader 更新自己状态为Leader,其他节点更新自己状态为 Follower。Leader 更新状态入口:leader.lead();Follower 更新状态入口:follower.followerLeader() 注意:
- follower 必须要让 leader 知道自己的状态:epoch、zxid、sid 必须要找出谁是leader;发起请求连接 leader;发送自己的信息给leader;leader 接收到信息,必须要返回对应的信息给 follower
- 当leader 得知follower 的状态了,就确定需要做何种方式的数据同步DIFF、TRUNC、SNAP
- 执行数据同步
- 当 leader 接收到超过半数 follower 的 ack 之后,进入正常工作状态,集群启动完成了
最终总结同步的方式:
- DIFF 咱两一样,不需要做什么
- TRUNC follower 的 zxid 比 leader 的 zxid 大,所以 Follower 要回滚
- COMMIT leader 的zxid 比 follower 的 zxid 大,发送 Proposal 给 foloower 提交执行
- 如果 follower 并没有任何数据,直接使用 SNAP 的方式来执行数据同步(直接把数据全部序列到follower)
6、服务端启动
6.1 Leader 启动
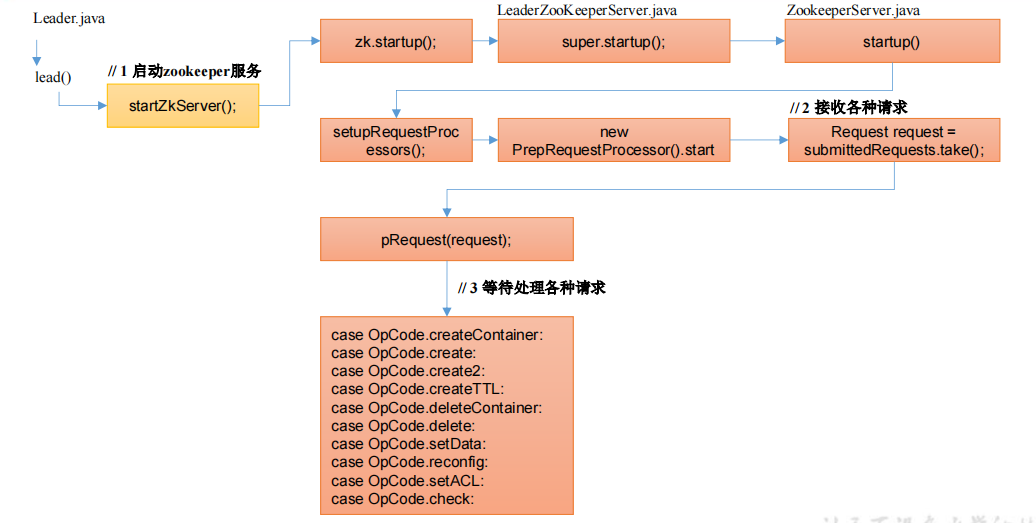
ZooKeeperServer全局查找 Leader,然后 ctrl + f 查找 lead()
1 | void lead() throws IOException, InterruptedException { |
6.2 Follower 启动

FollowerZooKeeperServer全局查找 Follower,然后 ctrl + f 查找 followLeader()
1 | void followLeader() throws InterruptedException { |
7、客户端启动
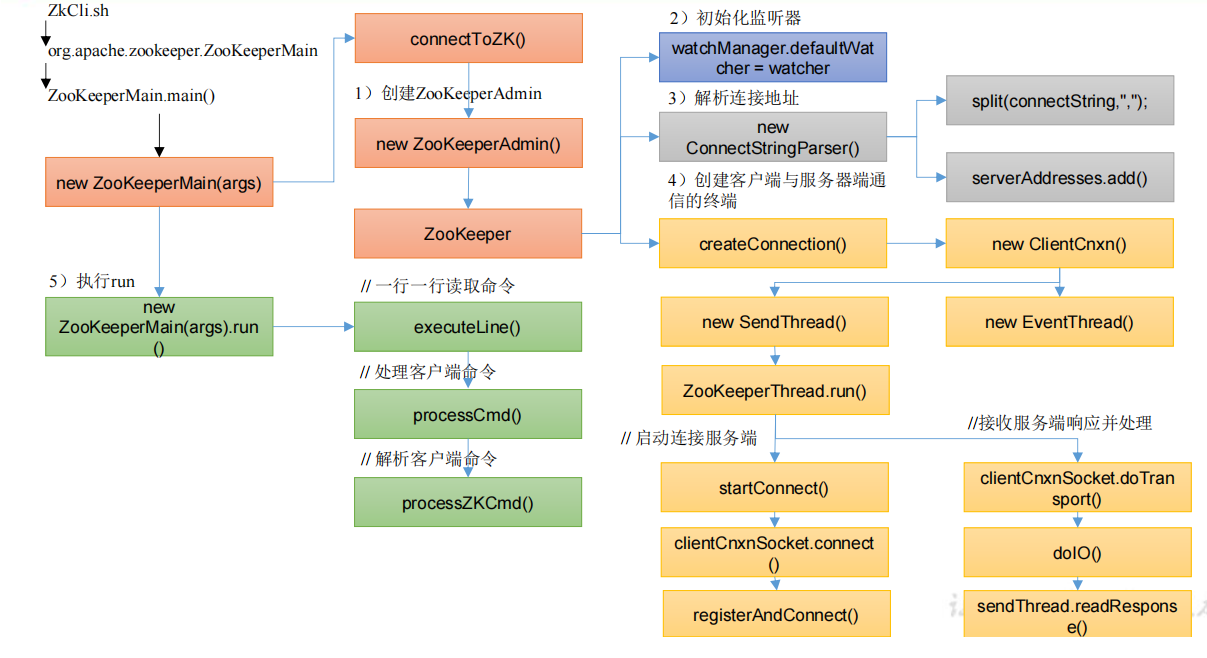
在 ZkCli.sh 启动 Zookeeper 时,会调用 ZooKeeperMain.java,查找 ZooKeeperMain,找到程序的入口 main()方法
1 | public static void main(String args[]) throws CliException, IOException, InterruptedException{ |
7.1 创建 ZookeeperMain
1 | public ZooKeeperMain(String args[]) throws IOException, InterruptedException { |
7.2 初始化监听器
ZooKeeperAdmin一直点进去
1 | public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, |
7.3 解析连接地址
1 | public ConnectStringParser(String connectString) { |
7.4 创建通信
1 | public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, |
点击SendThread,查找run方法
1 | // ZooKeeperThread 是一个线程,执行它的 run()方法 |
ctrl + alt +B 查找 connect 实现类,ClientCnxnSocketNIO.java
1 |
|
ctrl + alt +B 查找 doTransport 实现类,ClientCnxnSocketNIO.java
1 |
|
7.5 执行 run()
1 | public static void main(String args[]) throws CliException, IOException, InterruptedException{ |

