
离线数据同步Sqoop与DataX
一、Sqoop安装与使用
1、简介
Sqoop全称是 Apache Sqoop(现已经抛弃),是一个开源工具,能够将数据从数据存储空间(数据仓库,系统文档存储空间,关系型数据库)导入 Hadoop 的 HDFS或列式数据库HBase,供 MapReduce 分析数据使用。数据传输的过程大部分是通过 MapReduce 过程来实现,只需要依赖数据库的Schema信息Sqoop所执行的操作是并行的,数据传输性能高,具备较好的容错性,并且能够自动转换数据类型。
Sqoop是一个为高效传输海量数据而设计的工具,一般用在从关系型数据库同步数据到非关系型数据库中。Sqoop专门是为大数据集设计的。Sqoop支持增量更新,将新记录添加到最近一次的导出的数据源上,或者指定上次修改的时间戳。
2、Sqoop安装
1 | # 这里我使用了1.4.6为例子,1.4.7还需要common包 |
3、Sqoop实例
3.1 Mysql导入Hadoop
1 | # /opt/module/sqoop/bin |
3.2 Hadoop导出到Mysql
Sqoop export 工具将一组文件从 HDFS 导出回 Mysql 。目标表必须已存在于数据库中。根据用户指定的分隔符读取输入文件并将其解析为一组记录。默认操作是将这些转换为一组INSERT将记录注入数据库的语句。在“更新模式”中,Sqoop 将生成 UPDATE 替换数据库中现有记录的语句,并且在“调用模式”下,Sqoop 将为每条记录进行存储过程调用,将 HDFS、Hive、HBase的数据导出到 Mysql 表中,都会用到下表的参数:
| 参数 | 描述 |
|---|---|
| –table <table name> | 指定要导出的mysql目标表 |
| –export-dir <path> | 指定要导出的hdfs路径 |
| –input-fields-terminated-by <char> | 指定输入字段分隔符 |
| -m <数值> | 执行map任务的个数,默认是4个 |
1 | # =======================HDFS数据导出至Mysql======================== |
其他具体可以参考:sqoop学习,这一篇文章就够了 / Sqoop1.4.7实现将Mysql数据与Hadoop3.0数据互相抽取
二、DataX概述与入门
1、DataX概述
1.1 简介
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路, DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。DataX 目前已经有了比较全面的插件体系,主流的RDBMS 数据库、NOSQL、大数据计算系统都已经接入
1.2 框架设计
- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题
1.3 运行原理

举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张分表的 mysql 数据同步到 odps 里面。 DataX 的调度决策思路是:
- DataXJob 根据分库分表切分成了 100 个 Task
- 根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup
- 4 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责以 5 个并发共计运行 25 个 Task
2、DataX与 Sqoop 的对比
Sqoop已经被apache丢弃,后面建议都用datax
| 功****能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR |
| MySQL 读写 | 单机压力大; 读写粒度容易控制 | MR 模式重,写出错处理麻烦 |
| Hive 读写 | 单机压力大 | 很好 |
| 文件格式 | orc 支持 | orc 不支持,可添加 |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在 core 部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
| 社区 | 开源不久,社区不活跃 | 一直活跃,核心部分变动很少 |
3、快速入门
1 | # 需要jdk和python |
三、DataX常用入门案例
1、从stream 流读取数据并打印到控制台
1 | # 会显示出模板 |
2、读取 MySQL 中的数据存放到 HDFS
2.1 查看官方模板
1 | # https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md |


2.2 数据准备与配置
1 | mysql> create database datax; |
vim /opt/module/datax/job/mysql2hdfs.json这里我配置了ha
1 | { |
2.3 执行与结果
1 | python /opt/module/datax/bin/datax.py /opt/module/datax/job/mysql2hdfs.json |
3、读取 HDFS 数据写入 MySQL
https://github.com/alibaba/DataX/blob/master/hdfsreader/doc/hdfsreader.md
1 | # 改名 |
创建配置文件vim job/hdfs2mysql.json
1 | { |
对于hadoop高可用的配置
1 | "hadoopConfig":{ |
然后在 MySQL 的 datax 数据库中创建 student2
1 | mysql> use datax; |
开始执行python bin/datax.py job/hdfs2mysql.json
4、其他数据库
四、DataX源码分析
1、总体执行流程
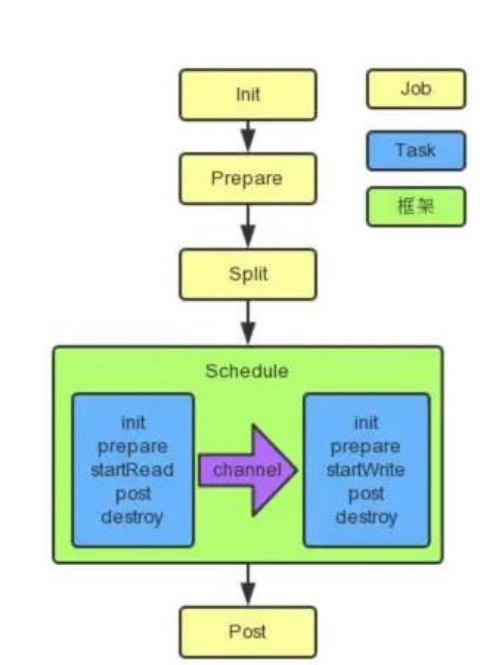
2、程序入口
1 | ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH) |
3、Task 切分逻辑
1 | /** |
4、调度
1 | //JobContainer.java |
5、数据传输
找到TaskGroupContainer.start()—> taskExecutor.doStart()
1 | public void doStart() { |
五、DataX 使用优化
1、关键参数
- job.setting.speed.channel : channel 并发数
- job.setting.speed.record : 全局配置 channel 的 record 限速
- job.setting.speed.byte:全局配置 channel 的 byte 限速
- core.transport.channel.speed.record:单个 channel 的 record 限速
- core.transport.channel.speed.byte:单个 channel 的 byte 限速
2、优化 1:提升每个 channel 的速度
在 DataX 内部对每个 Channel 会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是 1MB/s,可以根据具体硬件情况设置这个 byte 速度或者 record 速度,一般设置 byte 速度,比如:我们可以把单个 Channel 的速度上限配置为 5MB
3、优化 2:提升 DataX Job 内 Channel 并发数
并发数 = taskGroup 的数量 * 每个 TaskGroup 并发执行的 Task 数 (默认为 5)。提升 job 内 Channel 并发有三种配置方式:
3.1 配置全局 Byte 限速以及单 Channel Byte 限速
Channel 个数 = 全局 Byte 限速 / 单 Channel Byte 限速
1 | { |
core.transport.channel.speed.byte=1048576,job.setting.speed.byte=5242880,所以 Channel个数 = 全局 Byte 限速 / 单 Channel Byte 限速=5242880/1048576=5 个
3.2 配置全局 Record 限速以及单 Channel Record 限速
Channel 个数 = 全局 Record 限速 / 单 Channel Record 限速
1 | { |
core.transport.channel.speed.record=100 , job.setting.speed.record=500, 所 以 配 置 全 局Record 限速以及单 Channel Record 限速,Channel 个数 = 全局 Record 限速 / 单 ChannelRecord 限速=500/100=5
3.3 直接配置 Channel 个数
只有在上面两种未设置才生效,上面两个同时设置是取值小的作为最终的 channel 数
1 | { |
直接配置 job.setting.speed.channel=5,所以 job 内 Channel 并发=5 个
4、优化 3:提高 JVM 堆内存
当提升 DataX Job 内 Channel 并发数时,内存的占用会显著增加,因为 DataX 作为数据交换通道,在内存中会缓存较多的数据。例如 Channel 中会有一个 Buffer,作为临时的数据交换的缓冲区,而在部分 Reader 和 Writer 的中,也会存在一些 Buffer,为了防止 OOM 等错误,调大 JVM 的堆内存。
建议将内存设置为 4G 或者 8G,这个也可以根据实际情况来调整。调整 JVM xms xmx 参数的两种方式:一种是直接更改 datax.py 脚本;另一种是在启动的时候,加上对应的参数,如下:
1 | python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json |
六、DataX脚本
python生成datax配置文件脚本
1 | # coding=utf-8 |
1 | # 由于需要使用Python访问Mysql数据库,故需安装驱动 |
导出脚本
1 |
|

