
Redis接口限流、分布式锁与幂等
一、概述
1、Redis概述
Redis参考文章:Redis6.0学习笔记
Redis 除了做缓存,还能干很多很多事情:分布式锁、限流、处理请求接口幂等性,本篇文章重点讲述SpringBoot通过注解和AOP的方式实现Redis的接口限流,Redis使用了Lua脚本实现原子操作;通过redis实现的分布式锁以及处理接口幂等等方案
2、功能介绍
2.1 Redis限流
限流就是限制API访问频率,当访问频率超过某个阈值时进行拒绝访问等操作
当然这是在代码层面进行的接口限流,现在分布式微服务接口限流基本是在网关处做接口限流/黑白名单等,例如Gateway/Nginx等,详情可以参考Nginx高级篇和SpringCloud Gateway 详解
2.2 分布式锁
为了保证一个方法在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLcok或synchronized)进行互斥控制。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题
2.3 接口幂等
幂等性原本是数学上的概念,用在接口上就可以理解为:同一个接口,多次发出同一个请求,必须保证操作只执行一次。 调用接口发生异常并且重复尝试时,总是会造成系统所无法承受的损失,所以必须阻止这种现象的发生
二、Redis接口限流实战
1、环境准备
首先我们创建一个 Spring Boot 工程,引入 Web 和 Redis 依赖,同时考虑到接口限流一般是通过注解来标记,而注解是通过 AOP 来解析的,所以我们还需要加上 AOP 的依赖,最终的依赖如下
1 | <dependency> |
然后提前准备好一个** Redis 实例**,这里我们项目配置好之后,直接配置一下 Redis 的基本信息即可,如下:
1 | spring.redis.host=localhost |
2、限流注解
接下来我们创建一个限流注解,我们将限流分为两种情况:
-
针对当前接口的全局性限流,例如该接口可以在 1 分钟内访问 100 次
-
针对某一个 IP 地址的限流,例如某个 IP 地址可以在 1 分钟内访问 100 次
针对这两种情况,我们创建一个枚举类
1 | public enum LimitType { |
接下来我们来创建限流注解,第一个参数限流的 key,这个仅仅是一个前缀,将来完整的 key 是这个前缀再加上接口方法的完整路径,共同组成限流 key,这个 key 将被存入到 Redis 中
1 | (ElementType.METHOD) |
将来哪个接口需要限流,就在哪个接口上添加 @RateLimiter 注解,然后配置相关参数即可
3、配置RedisTemplate
默认的 RedisTemplate 有一个小坑,就是序列化用的是
JdkSerializationRedisSerializer,直接用这个序列化工具将来存到 Redis 上的 key 和 value 都会莫名其妙多一些前缀,这就导致你用命令读取的时候可能会出错,此时当你在命令行操作的时候,get name 却获取不到你想要的数据,原因就是存到 redis 之后 name 前面多了一些字符,此时只能继续使用 RedisTemplate 将之读取出来
因为Redis限流用到了Lua脚本,因此需要改写我们自己的序列化方案,使用 Spring Boot 中默认的 jackson 序列化方式来解决
1 |
|
4、开发 Lua 脚本
Redis 中的一些原子操作我们可以借助 Lua 脚本来实现,想要调用 Lua 脚本,我们有两种不同的思路
-
在 Redis 服务端定义好 Lua 脚本,然后计算出来一个散列值,在 Java 代码中,通过这个散列值锁定要执行哪个 Lua 脚本
-
直接在 Java 代码中将 Lua 脚本定义好,然后发送到 Redis 服务端去执行
Spring Data Redis 中也提供了操作 Lua 脚本的接口,还是比较方便的,所以我们这里就采用第二种方案,我们在 resources 目录下新建 lua 文件夹专门用来存放 lua 脚本
1 | local key = KEYS[1] |
这个lua脚本执行流程
-
首先获取到传进来的 key 以及 限流的 count 和时间 time
-
通过 get 获取到这个 key 对应的值,这个值就是当前时间窗内这个接口可以访问多少次
-
如果是第一次访问,此时拿到的结果为 nil,否则拿到的结果应该是一个数字,所以接下来就判断,如果拿到的结果是一个数字,并且这个数字还大于 count,那就说明已经超过流量限制了,那么直接返回查询的结果即可
-
如果拿到的结果为 nil,说明是第一次访问,此时就给当前 key 自增 1,然后设置一个过期时间
-
最后把自增 1 后的值返回
最后在Spring中加载这个Lua脚本
1 |
|
5、全局类与工具类
由于过载的时候是抛异常出来,所以我们还需要一个全局异常处理,其他详细可以参考Spring Boot后端接口规范
1 |
|
IpUtils工具类,获取Ip或者Mac
1 | public class IpUtils { |
6、注解AOP解析
下面的切面就是拦截所有加了 @RateLimiter 注解的方法,在前置通知中对注解进行处理。
-
首先获取到注解中的 key、time 以及 count 三个参数
-
获取一个组合的 key,所谓的组合的 key,就是在注解的 key 属性基础上,再加上方法的完整路径,如果是 IP 模式的话,就再加上 IP 地址。以 IP 模式为例,最终生成的 key 类似这样:
rate_limit:192.168.249.1-com.example.limiting.controller.HelloController-hello(如果不是 IP 模式,那么生成的 key 中就不包含 IP 地址) -
将生成的 key 放到集合中
-
通过
redisTemplate.execute方法取执行一个 Lua 脚本,第一个参数是脚本所封装的对象,第二个参数是 key,对应了脚本中的 KEYS,后面是可变长度的参数,对应了脚本中的 ARGV -
将 Lua 脚本执行的结果与 count 进行比较,如果大于 count,就说明过载了,抛异常就行了
1 |
|
7、接口测试
进行简单的测试,下面每一个 IP 地址,在 5 秒内只能访问 3 次
1 |
|
三、Redis分布式锁
1、简介
分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性。
分布式锁一般都使用Redis来实现,大概有以下几种方案,可以参考redis分布式锁
-
SETNX + EXPIRE
-
SETNX + value值是(系统时间+过期时间)
-
使用Lua脚本(包含SETNX + EXPIRE两条指令)
-
SET的扩展命令(SET EX PX NX)
-
SET EX PX NX + 校验唯一随机值,再释放锁 (推荐)
-
开源框架Redisson (推荐)
-
多机实现的分布式锁Redlock (推荐)
2、AOP分布式锁原理
2.1 实现流程
-
新建注解 @interface,在注解里设定入参标志
-
增加 AOP 切点,扫描特定注解
-
建立
@Aspect切面任务,注册 bean 和拦截特定方法 -
特定方法参数 ProceedingJoinPoint,对方法
pjp.proceed()前后进行拦截 -
切点前进行加锁,任务执行后进行删除 key
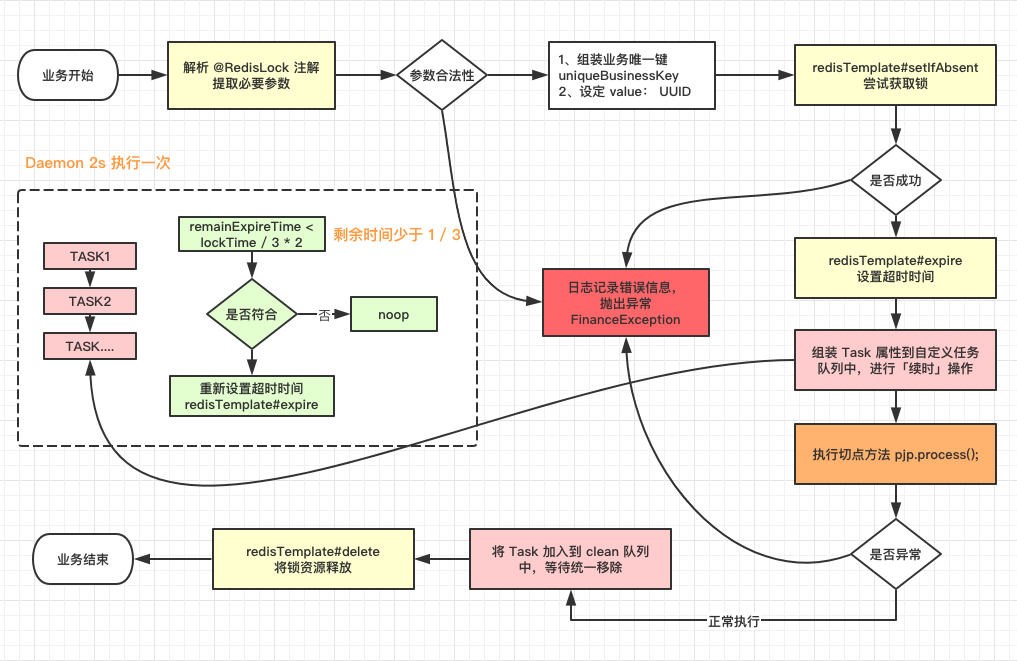
2.2 核心步骤
- 加锁
使用了 StringRedisTemplate 的 opsForValue.setIfAbsent 方法,判断是否有 key,设定一个随机数 UUID.random().toString,生成一个随机数作为 value。从 redis 中获取锁之后,对 key 设定 expire 失效时间,到期后自动释放锁。按照这种设计,只有第一个成功设定 Key 的请求,才能进行后续的数据操作,后续其它请求由于无法获得🔐资源,将会失败结束。
- 超时问题
担心 pjp.proceed() 切点执行的方法太耗时,导致 Redis 中的 key 由于超时提前释放了。例如,线程 A 先获取锁,proceed 方法耗时,超过了锁超时时间,到期释放了锁,这时另一个线程 B 成功获取 Redis 锁,两个线程同时对同一批数据进行操作,导致数据不准确。
- 锁续时操作(任务不完成,锁不释放)
维护了一个定时线程池 ScheduledExecutorService,每隔 2s 去扫描加入队列中的 Task,判断是否失效时间是否快到了,公式为:【失效时间】<= 【当前时间】+【失效间隔(三分之一超时)】
3、AOP分布式锁实战
3.1 业务属性枚举设定
环境与Redis限流一样,首先创建注解
1 | public enum RedisLockTypeEnum { |
3.2 任务队列保存参数
1 |
|
3.3 拦截的注解名声明
1 | (RetentionPolicy.RUNTIME) |
3.4 核心切面拦截
-
解析注解参数,获取注解值和方法上的参数值
-
redis 加锁并且设置超时时间
-
将本次 Task 信息加入「延时」队列中,进行续时,方式提前释放锁
-
加了一个线程中断标志
-
结束请求,finally 中释放锁
1 |
|
3.5 续时操作
这里加了「线程中断」Thread#interrupt,希望超过重试次数后,能让线程中断(仅供参考)
1 | 4j |
3.6 测试
在一个入口方法中,使用该注解,然后在业务中模拟耗时请求,使用了 Thread#sleep。使用时,在方法上添加该注解,然后设定相应参数即可,根据 typeEnum 可以区分多种业务,限制该业务被同时操作
1 |
|
4、Redission分布式锁(AOP实现)
Redission地址:https://github.com/redisson/redisson
首先需要引入相关依赖,这里需要额外引入redission依赖
1 | <dependency> |
在applicatiion.properties创建参数
1 | spring.redis.host=localhost |
4.1 注解创建
1 | (value = RetentionPolicy.RUNTIME) |
4.2 创建切面增强
1 |
|
4.3 测试
1 |
|
4.4 Redission其他
Redission还有以下几种锁以及集群操作,详情可以参考:springboot整合redission分布式锁的实现方式含集群解决方案(技术篇)
-
可重入锁(Reentrant Lock)
-
公平锁(Fair Lock)
-
读写锁(ReadWriteLock)
-
信号量(Semaphore)
-
闭锁(CountDownLatch)
四、Redis接口幂等
1、介绍
幂等性,就是只多次操作的结果是一致的
产生的问题
-
前端重复提交。比如这个业务处理需要2秒钟,我在2秒之内,提交按钮连续点了3次,如果非幂等性接口,那么后端就会处理3次。如果是查询,自然是没有影响的,因为查询本身就是幂等操作,但如果是新增,本来只是新增1条记录的,连点3次,就增加了3条,这显然不行。
-
响应超时而导致请求重试:在微服务相互调用的过程中,假如订单服务调用支付服务,支付服务支付成功了,但是订单服务接收支付服务返回的信息时超时了,于是订单服务进行重试,又去请求支付服务,结果支付服务又扣了一遍用户的钱。
解决方案
-
数据库记录状态机制:即每次操作前先查询状态,根据数据库记录的状态来判断是否要继续执行操作。比如订单服务调用支付服务,每次调用之前,先查询该笔订单的支付状态,从而避免重复操作。
-
token机制:请求业务接口之前,先请求token接口(会将生成的token放入redis中)获取一个token,然后请求业务接口时,带上token。在进行业务操作之前,我们先获取请求中携带的token,看看在redis中是否有该token,有的话,就删除,删除成功说明token校验通过,并且继续执行业务操作;如果redis中没有该token,说明已经被删除了,也就是已经执行过业务操作了,就不让其再进行业务操作。大致流程如下:
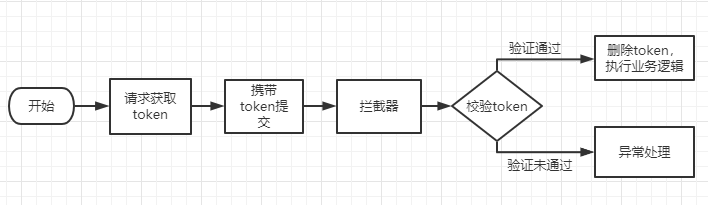
2、防重 Token 令牌流程
-
服务端提供获取 Token 的接口,该 Token 可以是一个序列号,也可以是一个分布式 ID 或者 UUID 串
-
客户端调用接口获取 Token,这时候服务端会生成一个 Token 串
-
然后将该串存入 Redis 数据库中,以该 Token 作为 Redis 的键(注意设置过期时间)
-
将 Token 返回到客户端,客户端拿到后应存到表单隐藏域中
-
客户端在执行提交表单时,把 Token 存入到 Headers 中,执行业务请求带上该 Headers
-
服务端接收到请求后从 Headers 中拿到 Token,然后根据 Token 到 Redis 中查找该 key 是否存在
-
服务端根据 Redis 中是否存该 key 进行判断,如果存在就将该 key 删除,然后正常执行业务逻辑。如果不存在就抛异常,返回重复提交的错误信息
3、放重Token实战
3.1 注解创建
1 | (ElementType.METHOD) //使用于方法 |
3.2 配置返回渲染
1 | public class ServletUtils |
3.3 放重Token生成与验证
1 | 4j |
3.4、配置拦截器
首先创建自定义拦截器
1 |
|
配置spring拦截器
1 |
|
3.5 测试
1 |
|
参考文章:

