
元数据管理Atlas
一、Atlas概述
1、Atlas入门
Apache Atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。同时可以配合ranger对某个元数据进行权限管理
| 元数据分类 | 支持对元数据进行分类管理,例如个人信息,敏感信息等 |
|---|---|
| 元数据检索 | 可按照元数据类型、元数据分类进行检索,支持全文检索 |
| 血缘依赖 | 支持表到表和字段到字段之间的血缘依赖,便于进行问题回溯和影响分析等 |
例如表与表之间的血缘依赖
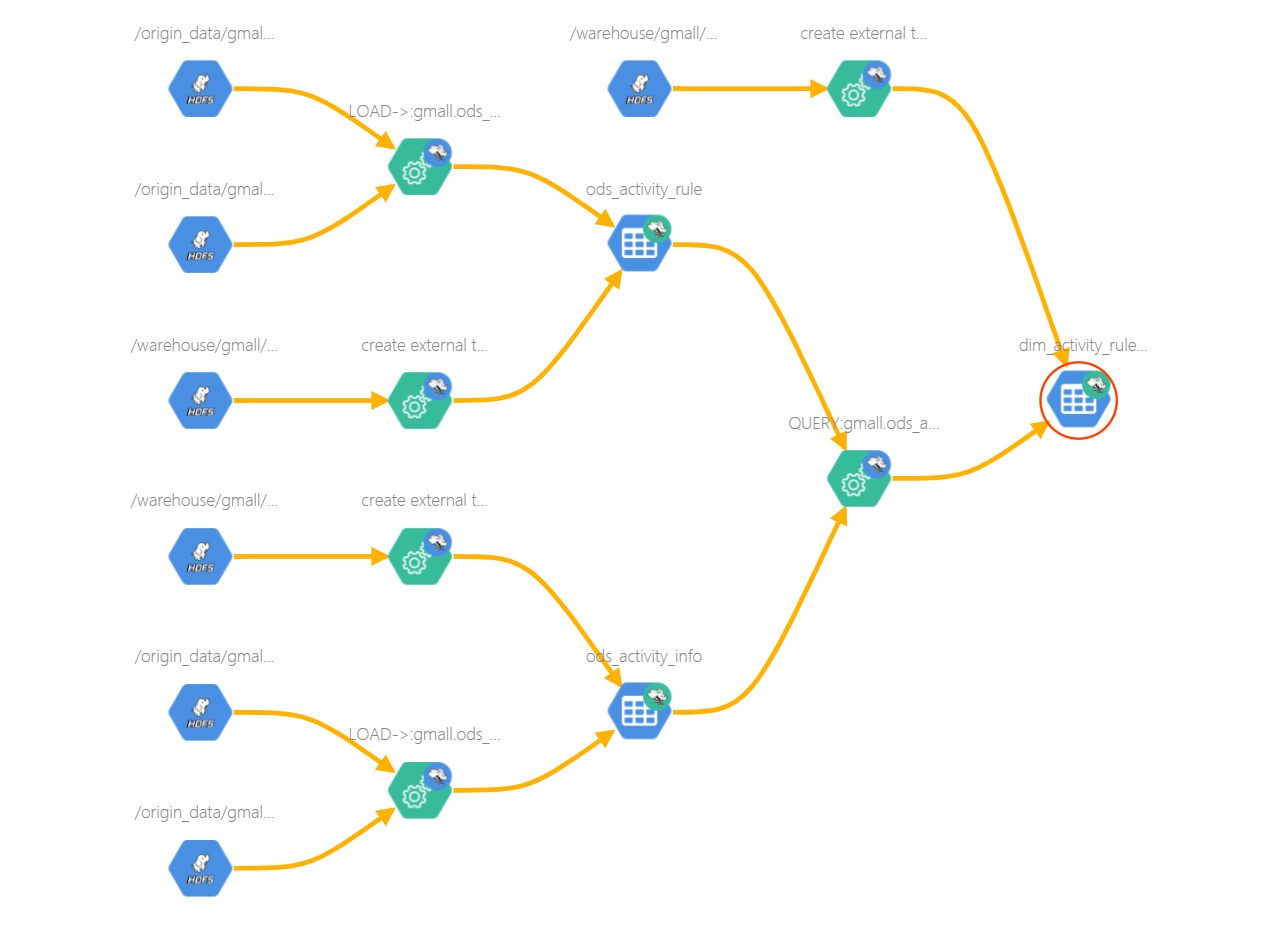
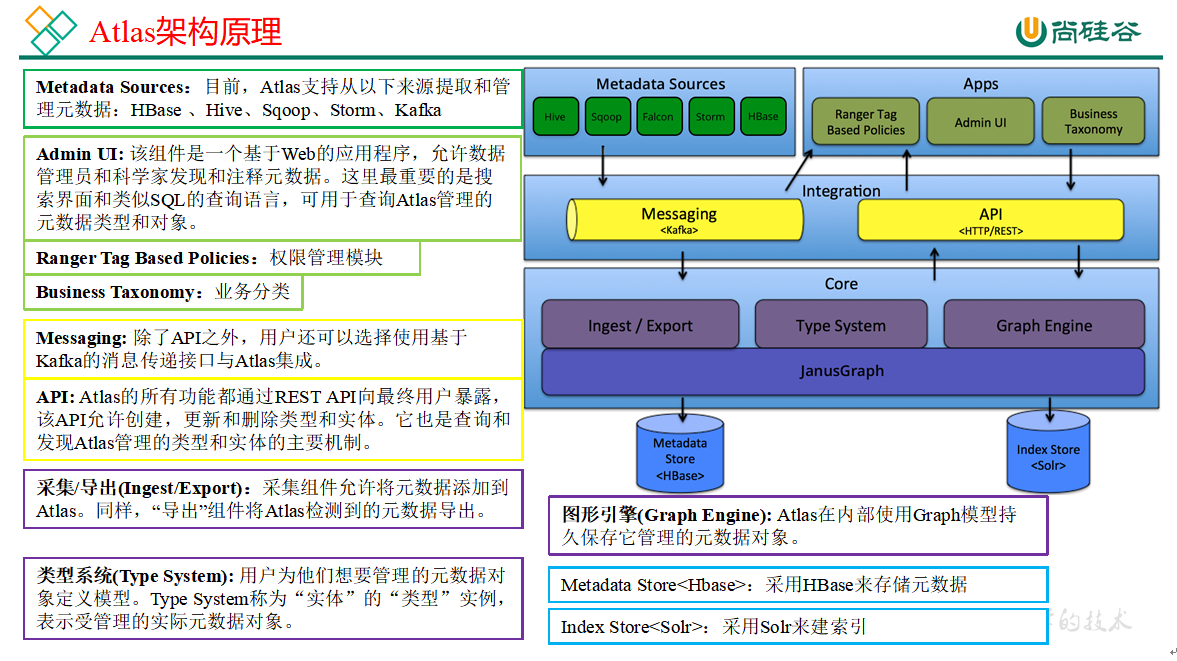
2、Atlas架构原理
二、Atlas安装
Atlas官网地址:https://atlas.apache.org/
文档查看地址:https://atlas.apache.org/2.1.0/index.html
下载地址:https://www.apache.org/dyn/closer.cgi/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
1、安装环境准备
Atlas安装分为:集成自带的HBase + Solr;集成外部的HBase + Solr。通常企业开发中选择集成外部的HBase + Solr,方便项目整体进行集成操作
| 服务名称 | 子服务 | 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 |
|---|---|---|---|---|
| JDK | √ | √ | √ | |
| Zookeeper | QuorumPeerMain | √ | √ | √ |
| Kafka | Kafka | √ | √ | √ |
| HBase | HMaster | √ | ||
| HRegionServer | √ | √ | √ | |
| Solr | Jar | √ | √ | √ |
| Hive | Hive | √ | ||
| Atlas | atlas | √ | ||
| 服务数总计 | 13 | 7 | 7 |
1.1 安装Solr-7.7.3
1 | # 在每台节点创建系统用户solr,三台机器都创建 |
1.2 Atlas2.1.0安装
1 | # 文档:https://atlas.apache.org/#/BuildInstallation |
2、Atlas配置
2.1 Atlas集成Hbase
1 | # 修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数 |
2.2 Atlas集成Solr
1 | # 修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数 |
2.3 Atlas集成Kafka
1 | # 修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数 |
2.4 Atlas Server配置
1 | # 修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数 |
记录性能指标,进入/opt/module/atlas/conf/路径,修改当前目录下的atlas-log4j.xml
1 | <!--去掉如下代码的注释--> |
2.5 Kerberos相关配置
若Hadoop集群开启了Kerberos认证,Atlas与Hadoop集群交互之前就需要先进行Kerberos认证。若Hadoop集群未开启Kerberos认证,则本节可跳过。
1 | # 为Atlas创建Kerberos主体,并生成keytab文件 |
2.6 Atlas集成Hive
1 | # 解压Hive Hook |
3、Atlas启动
1 | # 启动Atlas所依赖的环境 |
三、Atlas使用
1、介绍
Atlas的使用相对简单,其主要工作是同步各服务(主要是Hive)的元数据,并构建元数据实体之间的关联关系,然后对所存储的元数据建立索引,最终未用户提供数据血缘查看及元数据检索等功能。
Atlas在安装之初,需手动执行一次元数据的全量导入,后续Atlas便会利用Hive Hook增量同步Hive的元数据。
2、Hive元数据初次导入
Atlas提供了一个Hive元数据导入的脚本,直接执行该脚本,即可完成Hive元数据的初次全量导入。
1 | # 导入Hive元数据 |
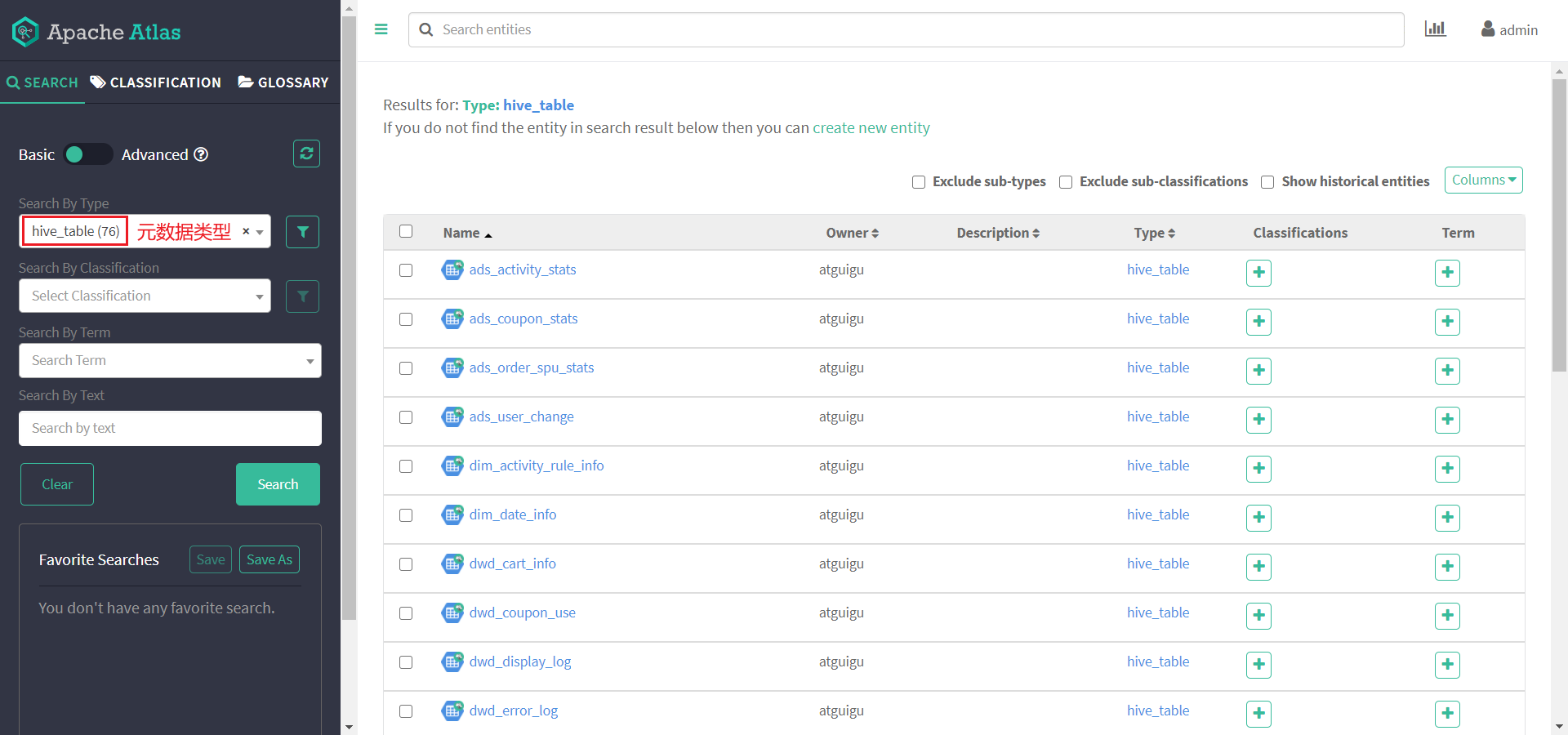
任选一张表查看血缘依赖关系,发现此时并未出现期望的血缘依赖,原因是Atlas是根据Hive所执行的SQL语句获取表与表之间以及字段与字段之间的依赖关系的,例如执行insert into table_a select * from table_b语句,Atlas就能获取table_a与table_b之间的依赖关系。此时并未执行任何SQL语句,故还不能出现血缘依赖关系
3、Hive元数据增量同步
Hive元数据的增量同步,无需人为干预,只要Hive中的元数据发生变化(执行DDL语句),Hive Hook就会将元数据的变动通知Atlas。除此之外,Atlas还会根据DML语句获取数据之间的血缘关系
四、扩展内容
1、Atlas源码编译
1.1 安装Maven
1 | # Maven下载:https://maven.apache.org/download.cgi |
修改setting.xml,指定为阿里云vim /opt/module/maven/conf/settings.xml
1 | <!-- 添加阿里云镜像--> |
1.2 编译Atlas源码
https://www.apache.org/dyn/closer.cgi/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
1 | # 把apache-atlas-2.1.0-sources.tar.gz上传到hadoop102的/opt/software目录下 |
2、Atlas内存配置
如果计划存储数万个元数据对象,建议调整参数值获得最佳的JVM GC性能。以下是常见的服务器端选项
1 | # 修改配置文件/opt/module/atlas/conf/atlas-env.sh |
3、配置用户名密码
Atlas支持以下身份验证方法:File、Kerberos协议、LDAP协议,通过修改配置文件atlas-application.properties文件开启或关闭三种验证方法
1 | atlas.authentication.method.kerberos=true|false |
如果两个或多个身份证验证方法设置为true,如果较早的方法失败,则身份验证将回退到后一种方法。例如,如果Kerberos身份验证设置为true并且ldap身份验证也设置为true,那么,如果对于没有kerberos principal和keytab的请求,LDAP身份验证将作为后备方案。
本文主要讲解采用文件方式修改用户名和密码设置。其他方式可以参见官网配置即可。
1 | # 打开/opt/module/atlas/conf/users-credentials.properties文件 |

