
安全认证Kerberos详解
一、Kerberos入门与使用
hadoop官网:https://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-common/SecureMode.html
1、Kerberos概述
1.1 什么是Kerberos
Kerberos是一种计算机网络认证协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。这个词又指麻省理工学院为这个协议开发的一套计算机软件。软件设计上采用客户端/服务器结构,并且能够进行相互认证,即客户端和服务器端均可对对方进行身份认证。可以用于防止窃听、防止重放攻击、保护数据完整性等场合,是一种应用对称密钥体制进行密钥管理的系统
1.2 Kerberos术语
Kerberos中有以下一些概念需要了解:
- KDC(Key Distribute Center):密钥分发中心,负责存储用户信息,管理发放票据
- Realm:Kerberos所管理的一个领域或范围,称之为一个Realm
- Rrincipal:Kerberos所管理的一个用户或者一个服务,可以理解为Kerberos中保存的一个账号,其格式通常如下:primary**/**instance@realm
- keytab:Kerberos中的用户认证,可通过密码或者密钥文件证明身份,keytab指密钥文件
1.3 Kerberos认证原理

2、Kerberos安装
2.1 安装Kerberos相关服务
1 | # 需要进入root用户 |
2.2 修改配置文件
1 | # 服务端主机(hadoop102) |
2.3 其他配置与启动
1 | # 初始化KDC数据库 |
3、Kerberos使用概述
3.1 Kerberos数据库操作
1 | # 本地登录(无需认证) |
3.2 Kerberos认证操作
1 | # 密码认证 |
一些常用操作
1 | # 1、密码形式创建kdc用户 |
二、Hadoop Kerberos配置
1、创建Hadoop系统用户
为Hadoop开启Kerberos,需为不同服务准备不同的用户,启动服务时需要使用相应的用户。须在所有节点创建以下用户和用户组
| User:Group | Daemons |
|---|---|
| hdfs:hadoop | NameNode, Secondary NameNode, JournalNode, DataNode |
| yarn:hadoop | ResourceManager, NodeManager |
| mapred:hadoop | MapReduce JobHistory Server |
1 | # 创建hadoop组,分别在三台机器创建 |
2、Hadoop Kerberos配置
2.1 为Hadoop各服务创建Kerberos主体(Principal)
主体格式如下:ServiceName/HostName@REALM,例如dn/hadoop102@EXAMPLE.COM
| 服务 | 所在主机 | 主体(Principal) |
|---|---|---|
| NameNode | hadoop102 | nn/hadoop102 |
| DataNode | hadoop102 | dn/hadoop102 |
| DataNode | hadoop103 | dn/hadoop103 |
| DataNode | hadoop104 | dn/hadoop104 |
| Secondary NameNode | hadoop104 | sn/hadoop104 |
| ResourceManager | hadoop103 | rm/hadoop103 |
| NodeManager | hadoop102 | nm/hadoop102 |
| NodeManager | hadoop103 | nm/hadoop103 |
| N****odeManager | hadoop104 | nm/hadoop104 |
| JobHistory Server | hadoop102 | jhs/hadoop102 |
| W****eb UI | hadoop102 | HTTP/hadoop102 |
| W****eb UI | hadoop103 | HTTP/hadoop103 |
| W****eb UI | hadoop104 | HTTP/hadoop104 |
创建主体说明
1 | # 为服务创建的主体,需要通过密钥文件keytab文件进行认证,故需为各服务准备一个安全的路径用来存储keytab文件 |
开始创建主体
1 | # 在所有节点创建keytab文件目录,三台机器执行 |
2.2 修改Hadoop配置文件
需要修改的内容如下(添加),修改完毕需要分发所改文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
1 | <!-- Kerberos主体到系统用户的映射机制 --> |
vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
1 | <!-- 访问DataNode数据块时需通过Kerberos认证 --> |
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
1 | <!-- Resource Manager 服务的Kerberos主体 --> |
vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
1 | <!-- 历史服务器的Kerberos主体 --> |
最后分发四个文件
1 | xsync /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml |
2.3 配置HDFS使用HTTPS安全传输协议
1 | # Keytool是java数据证书的管理工具,使用户能够管理自己的公/私钥对及相关证书。 |
1 | <!-- SSL密钥库路径 --> |
最后分发xsync $HADOOP_HOME/etc/hadoop/ssl-server.xml
2.4 配置Yarn使用LinuxContainerExecutor
因为默认提交任务的用户是启动hadoop的用户,因此需要把它改为提交者的用户
修改所有节点的container-executor所有者和权限,要求其所有者为root,所有组为hadoop(启动NodeManger的yarn用户的所属组),权限为6050。其默认路径为$HADOOP_HOME/bin
1 | # 三台机器依次执行 |
修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件,vim $HADOOP_HOME/etc/hadoop/yarn-site.xml,增加内容
1 | <!-- 配置Node Manager使用LinuxContainerExecutor管理Container --> |
最后分发
1 | xsync $HADOOP_HOME/etc/hadoop/container-executor.cfg |
3、安全模式下启动Hadoop集群
3.1 修改特定本地路径权限
因为是不同的用户分别启动不同的程序,所以需要修改之前的所有者和权限
| local | $HADOOP_LOG_DIR | hdfs:hadoop | drwxrwxr-x |
|---|---|---|---|
| local | dfs.namenode.name.dir | hdfs:hadoop | drwx------ |
| local | dfs.datanode.data.dir | hdfs:hadoop | drwx------ |
| local | dfs.namenode.checkpoint.dir | hdfs:hadoop | drwx------ |
| local | yarn.nodemanager.local-dirs | yarn:hadoop | drwxrwxr-x |
| local | yarn.nodemanager.log-dirs | yarn:hadoop | drwxrwxr-x |
1 | # $HADOOP_LOG_DIR(所有节点),三台机器依次运行 |
3.2 启动HDFS
1 | # =================== 单点启动 ================ |
3.3 改HDFS特定路径访问权限
| hdfs | / | hdfs:hadoop | drwxr-xr-x |
|---|---|---|---|
| hdfs | /tmp | hdfs:hadoop | drwxrwxrwxt |
| hdfs | /user | hdfs:hadoop | drwxrwxr-x |
| hdfs | yarn.nodemanager.remote-app-log-dir | yarn:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.intermediate-done-dir | mapred:hadoop | drwxrwxrwxt |
| hdfs | mapreduce.jobhistory.done-dir | mapred:hadoop | drwxrwx— |
若上述路径不存在,需手动创建
1 | # 以下操作都在hadoop102 |
3.4 启动Yarn
1 | # ==============单点启动================ |
3.5 启动HistoryServer
1 | # 启动历史服务器 |
4、启动遇坑详解
4.1 DataNode无法连接上NameNode 提示 : GSS initiate failed
1 | # 查看namenode的报错信息 |
原因是JDK没有装JCE组件, JDK需要下载安装JCE组件. 重启服务即可;或者使用使用JDK 1.8.0_161或更高版本时,不需要再安装JCE Policy File,因为JDK 1.8.0_161默认启用无限强度加密。
1 | # JCE的安装 |
4.2 Hadoop集成kerberos后,报错:AccessControlException
1 | # 报错信息 |
解决方法:修改 Kerboeros配置文件 /etc/krb5.conf , 注释掉 : default_ccache_name 属性,然后执行kdestroy,重新kinit
可以参考:https://blog.csdn.net/zhanglong_4444/article/details/115268262
5、安全集群使用说明
5.1 用户要求
以下使用说明均基于普通用户,安全集群对用户有以下要求:
- 集群中的每个节点都需要创建该用户
- 该用户需要属于hadoop用户组
- 需要创建该用户对应的Kerberos主体
1 | # 创建用户(存在可跳过),须在所有节点执行 |
5.2 访问HDFS集群文件
首先针对是shell环境
1 | # 认证 |
对于web页面
1 | # 下载认证客户端(windows),然后安装好 |
配置火狐浏览器(其他浏览器有可能有问题),打开浏览器,在地址栏输入about:config,点击回车;搜索network.negotiate-auth.trusted-uris,修改值为要访问的主机名(hadoop102);下一步搜索network.auth.use-sspi,双击将值变为false
最后启动认证,启动Kerberos客户端,点击Get Ticket,输入主体名和密码,点击OK,认证成功,访问web界面
5.3 提交MapReduce任务
1 | # 认证 |
三、Hive安全认证
1、Hive用户认证配置
1.1 创建Hive系统用户和Kerberos主体
hive作为服务来进行Kerberos认证
1 | # 创建系统用户,三台机器都要创建 |
1.2 配置认证
修改$HIVE_HOME/conf/hive-site.xml文件,vim $HIVE_HOME/conf/hive-site.xml,增加如下属性
1 | <!-- HiveServer2启用Kerberos认证 --> |
修改$HADOOP_HOME/etc/hadoop/core-site.xml文件,vim $HADOOP_HOME/etc/hadoop/core-site.xml
删除以下参数
1 | <property> |
增加以下参数
1 | <property> |
1 | # 分发配置core-site.xml文件 |
1.3 启动hiveserver2
1 | # 注:需使用hive用户启动 |
2、Hive Kerberos认证使用说明
以下说明均基于普通用户
2.1 beeline客户端
1 | # 认证,执行以下命令,并按照提示输入密码 |
2.2 DataGrip客户端
首先需要新建driver(自带的没有认证功能),配置Driver,url模板:jdbc:hive2://{host}:{port}/{database}[;<;,{:identifier}={:param}>](注意jar包路径)
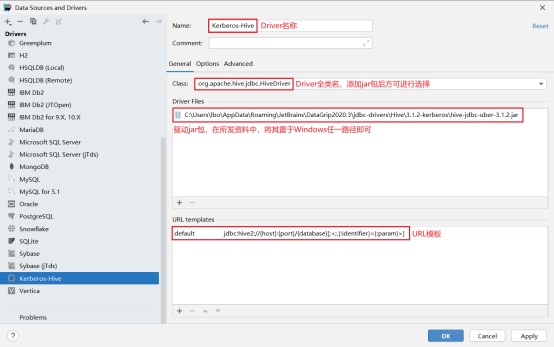
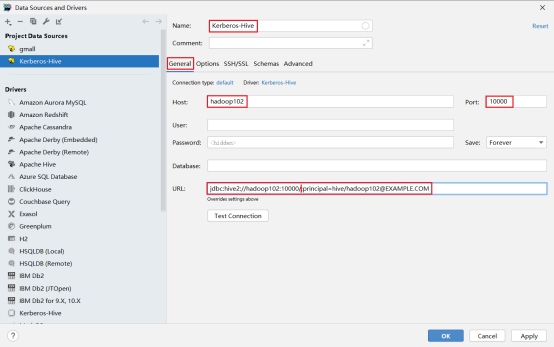
第二步新建连接,选择刚刚创建的driver,选择配置连接,url:jdbc:hive2://hadoop102:10000/;principal=hive/hadoop102@EXAMPLE.COM
选择高级配置,配置参数,注意路径要有文件
1 | -Djava.security.krb5.conf="C:\\ProgramData\\MIT\\Kerberos5\\krb5.ini" |
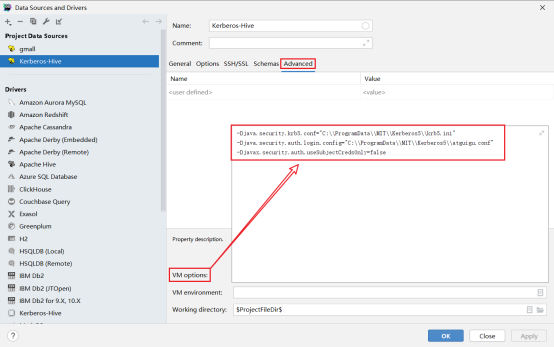
编写JAAS(Java认证授权服务)配置文件,内容如下,文件名和路径须和上图中java.security.auth.login.config参数的值保持一致。
1 | com.sun.security.jgss.initiate{ |
为用户生成keytab文件,在krb5kdc所在节点(hadoop102)执行以下命令,然后将生成的atguigu.keytab文件,置于Windows中的特定路径,测试连接
1 | kadmin.local -q"xst -norandkey -k /home/shawn/shawn.keytab shawn" |
四、安全环境实战
Hadoop启用Kerberos安全认证之后,之前的非安全环境下的全流程调度脚本和即席查询引擎均会遇到认证问题,故需要对其进行改进,本章内容仅限参考,具体可以参考官网
1、数仓全流程改造
此处统一将数仓的全部数据资源的所有者设为hive用户,全流程的每步操作均认证为hive用户
1.1 用户准备
1 | # 在各节点创建hive用户,如已存在则跳过,三个节点 |
1.2 数据采集通道修改
1 | # 修改/opt/module/flume/conf/kafka-flume-hdfs.conf配置文件, |
1.3 修改HDFS特定路径所有者
1 | # 认证为hdfs用户,执行以下命令并按提示输入密码 |
1.4 Azkaban举例
1 | # 在各节点创建azkaban用户 |
2、即席查询之Presto
2.1 改动说明
Presto集群开启Kerberos认证可只配置Presto Coordinator和Presto Cli之间进行认证,集群内部通讯可不进行认证。Presto Coordinator和Presto Cli之间的认证要求两者采用更为安全的HTTPS协议进行通讯。
若Presto对接的是Hive数据源,由于其需要访问Hive的元数据和HDFS上的数据文件,故也需要对Hive Connector进行Kerberos认证
2.2 用户准备
1 | # 在所有节点创建presto系统用户 |
2.3 创建HTTPS协议所需的密钥对
1 | # 注意: |
2.4 修改Presto Coordinator配置文件
在/opt/module/presto/etc/config.properties文件中增加以下参数
1 | http-server.authentication.type=KERBEROS |
2.5 修改Hive Connector配置文件
在/opt/module/presto/etc/catalog/hive.properties中增加以下参数
1 | hive.metastore.authentication.type=KERBEROS |
分发/opt/module/presto/etc/catalog/hive.properties文件
1 | xsync /opt/module/presto/etc/catalog/hive.properties |
2.6 配置客户端Kerberos主体到用户名之间的映射规则
新建/opt/module/presto/etc/access-control.properties配置文件
1 | access-control.name=file |
新建/opt/module/presto/etc/rules.json文件,内容如下
1 | { |
2.7 配置Presto代理用户
1 | # 修改Hadoop配置文件 |
2.8 重启Presto集群
1 | # 关闭集群,三台机器依次执行 |
2.9 客户端认证访问Presto集群
1 | # 102机器执行 |
3、即席查询之Kylin
3.1 改动说明
从Kylin的架构,可以看出Kylin充当只是一个Hadoop客户端,读取Hive数据,利用MR或Spark进行计算,将Cube存储至HBase中。所以在安全的Hadoop环境下,Kylin不需要做额外的配置,只需要具备一个Kerberos主体,进行常规的认证即可
但是Kylin(这里的kylin版本为3.x)所依赖的HBase需要进行额外的配置,才能在安全的Hadoop环境下正常工作
3.2 HBase开启Kerberos认证
首先进行用户准备
1 | # 在各节点创建hbase系统用户 |
修改HBase配置文件,修改$HBASE_HOME/conf/hbase-site.xml配置文件,增加以下参数
1 | <property> |
1 | # 分发配置文件 |
3.3 Kylin进行Kerberos认证
1 | # 用户准备,创建kylin系统用户,102机器 |

