
MyBatis源码分析
一、前言
MyBatis官方文档:https://mybatis.org/mybatis-3/zh/
1、介绍
对于MyBatis,其工作流程实际上分为两部分:第一,构建,也就是解析我们写的xml配置,将其变成它所需要的对象。第二,执行,在构建完成的基础上,去执行我们的SQL,完成与Jdbc的交互
2、快速上手
数据库配置如Mybatis学习笔记一样,我的项目结构如下图所示
创建mybatis-config.xml文件
1 |
|
创建db.properties外部文件
1 | jdbc.driver=com.mysql.cj.jdbc.Driver |
创建EmployeeMapper.xml文件
1 |
|
创建测试文件
1 | public static void main(String[] args) throws IOException { |
二、Mybatis的构建
1、核心流程
1.1 介绍
Configuration 是整个MyBatis的配置体系集中管理中心,前面所学Executor、StatementHandler、Cache、MappedStatement…等绝大部分组件都是由它直接或间接的创建和管理。其主要作用如下
- 存储全局配置信息,其来源于settings(设置)
- 初始化并维护全局基础组件
- typeAliases(类型别名)
- typeHandlers(类型处理器)
- plugins(插件)
- environments(环境配置)
- cache(二级缓存空间)
- 初始化并维护MappedStatement
- 组件构造器,并基于插件进行增强
- newExecutor(执行器)
- newStatementHandler(JDBC处理器)
- newResultSetHandler(结果集处理器)
- newParameterHandler(参数处理器)
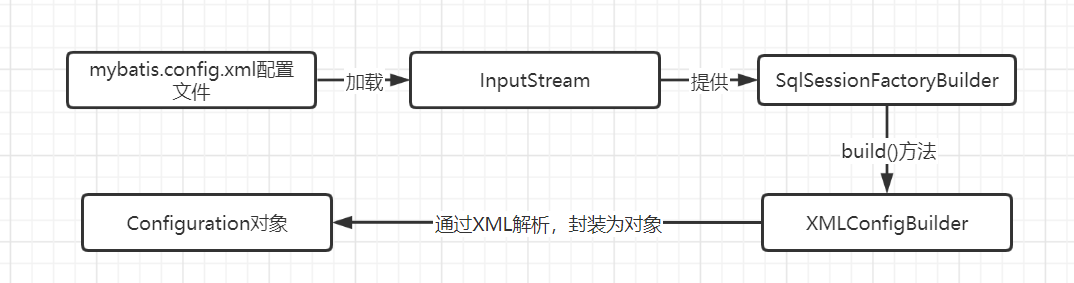
Configuration 配置信息来源于xml和注解,每个文件和注解都是由若干个配置元素组成,并呈现嵌套关系,总体关系如下图所示,关于各配置的使用请参见官网给出文档:https://mybatis.org/mybatis-3/zh/configuration.html#properties
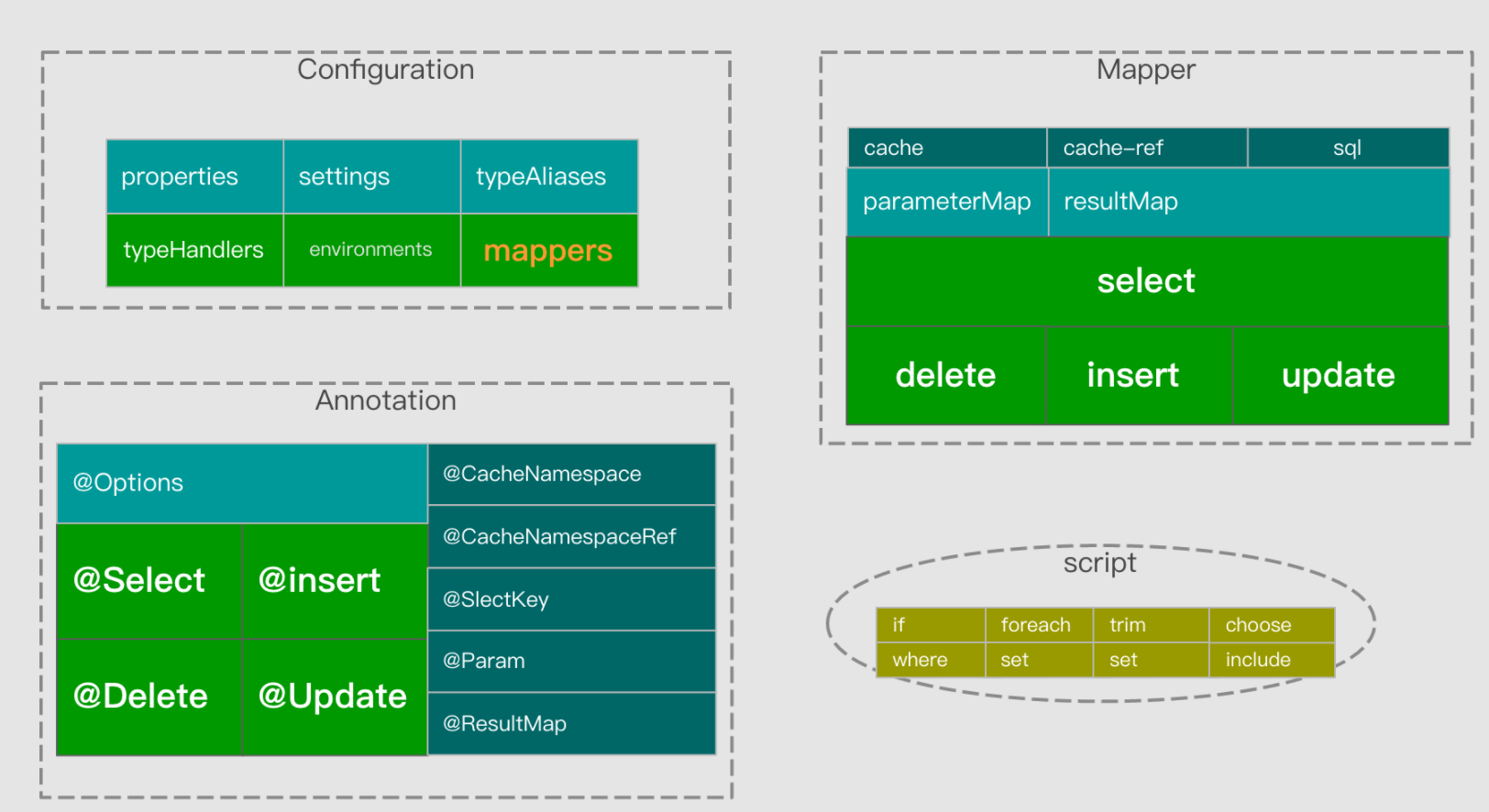
无论是xml 注解这些配置元素最弱都要被转换成JAVA配置属性或对象组件来承载。其对应关系如下:
- 全配置(config.xml) 由Configuration对像属性承载
- sql映射<select|insert…> 或@Select 等由MappedStatement对象承载
- 缓存<cache…> 或@CacheNamespace 由Cache对象承载
- 结果集映射 由ResultMap 对象承载

1.2 配置文件解析
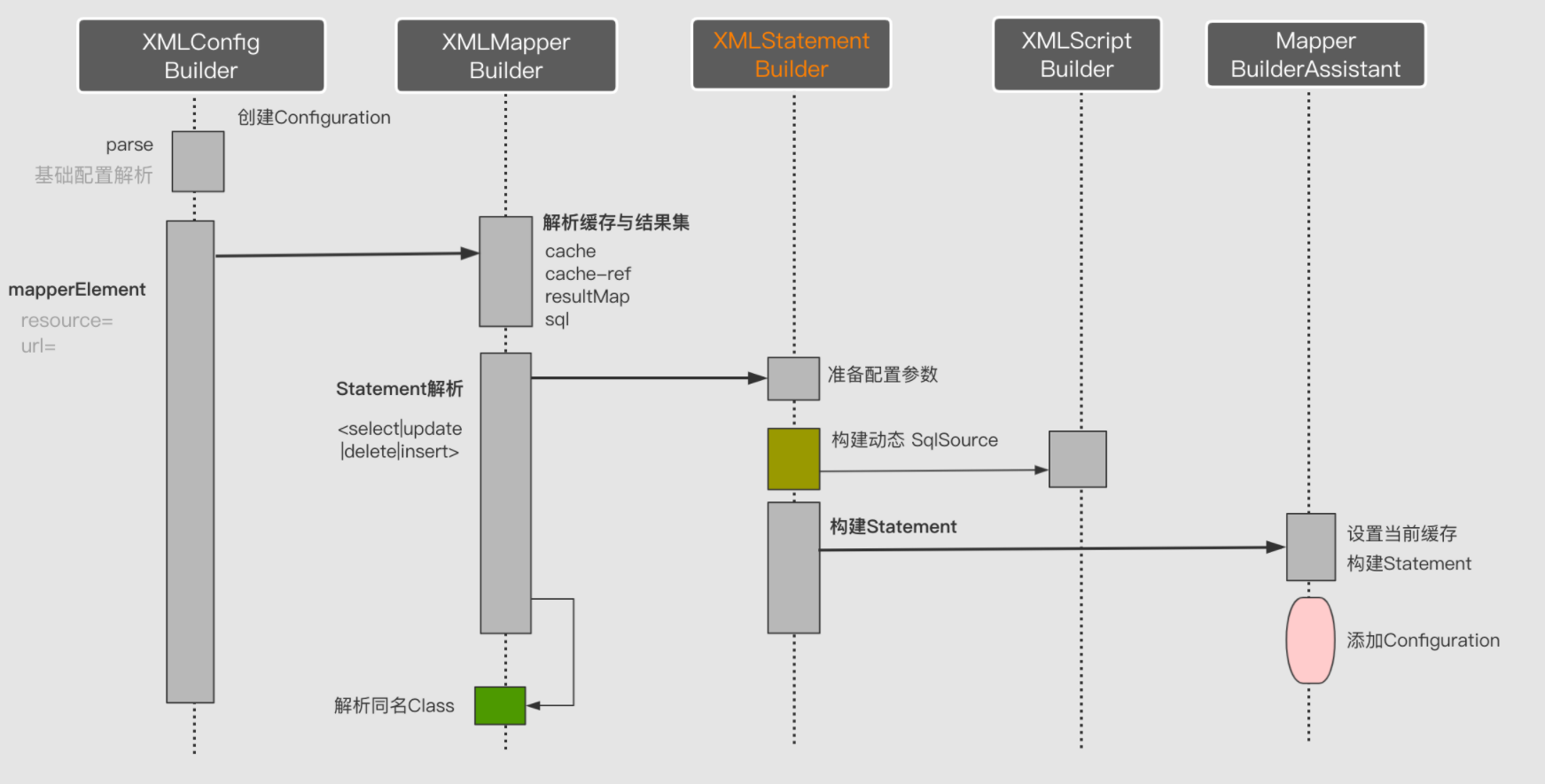
- XMLConfigBuilder :解析config.xml文件,会直接创建一个configuration对象,用于解析全局配置
- XMLMapperBuilder :解析Mapper.xml文件,内容包含等
- MapperBuilderAssistant:Mapper.xml解析辅助,在一个Mapper.xml中Cache是对Statement(sql声明)共享的,共享组件的分配即由该解析实现
- XMLStatementBuilder:SQL映射解析 即<select|update|insert|delete> 元素解析成MapperStatement
- SqlSourceBuilder:Sql数据源解析,将声明的SQL解析可执行的SQL
- XMLScriptBuilder:解析动态SQL数据源当中所设置 SqlNode脚本集
XML文件解析流程
整体解析流程是从XmlConfigBuilder 开始,然后逐步向内解析,直到解析完所有节点。我们通过一个MappedStatement 解析过程即可了解到期整体解析流程
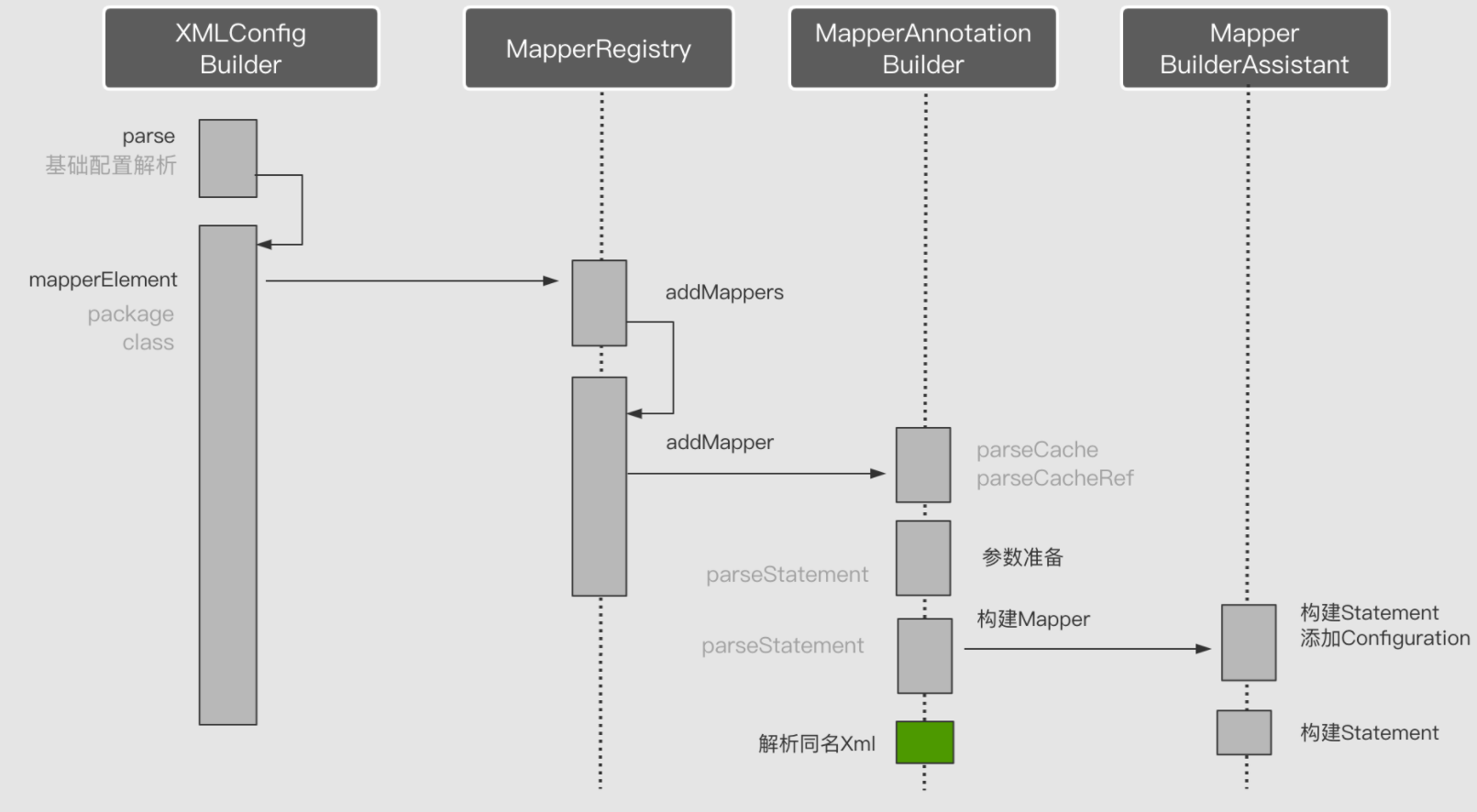
注解配置解析
注解解析底层实现是通过反射获取Mapper接口当中注解元素实现。有两种方式一种是直接指定接口名,一种是指定包名然后自动扫描包下所有的接口类。这些逻辑均由Mapper注册器(MapperRegistry)实现。其接收一个接口类参数,并基于该参数创建针对该接口的动态代理工厂,然后解析内部方法注解生成每个MapperStatement 最后添加至Configuration 完成解析。
1.3 源码分析
进入build方法,可以看见代码将xml文件传入并返回了一个SqlSessionFactory对象,而这个对象是使用构造者模式创建的。
1 | public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) { |
在进入build对象的parse()方法,这个方法初始化Configuration对象,并且解析xml文件,把解析内容放入到Configuration对象中。其中就包括别名的映射,在初始化阶段别名映射会自动注册一些常用的别名,如果我们自己也配置也自动注册到Configuration对象的TypeAliasRegistry的TYPE_ALIASES的map中,并且把数据源和事务解析以后放入到Environment,给后续的执行提供数据链接和事务管理。
1 | public Configuration parse() { |
在进入parseConfiguration()方法,可以看到这个方法已经在解析<configuration>下的节点了,例如<settings>,<typeAliases>,<environments>和<mappers>等,同时返回了Configuration对象
1 | // root即是完整的xml内容 |
2、Configuration对象详解
2.1 配置文件dataSource 内容替换
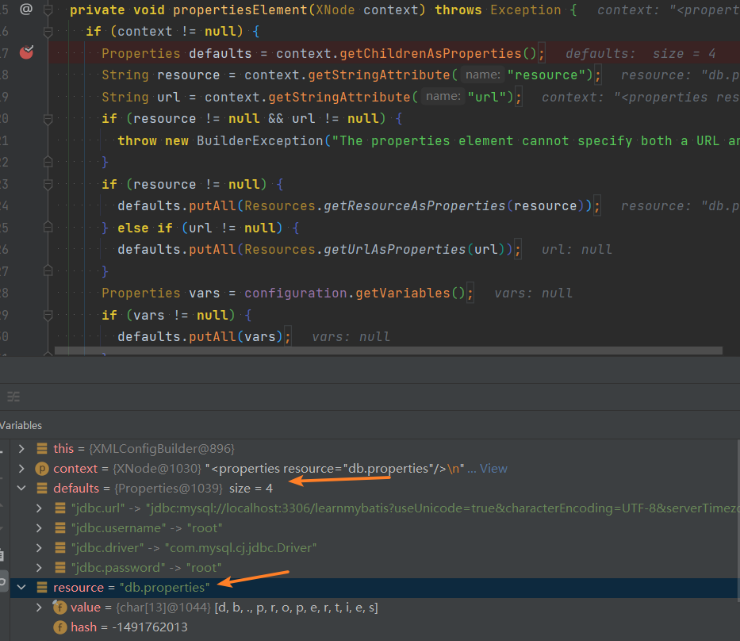
对于db.properties替代,在parseConfiguration()方法中的propertiesElement(root.evalNode("properties"));就是对外部配置文件的替换修改,它首先形成Properties对象对其替换
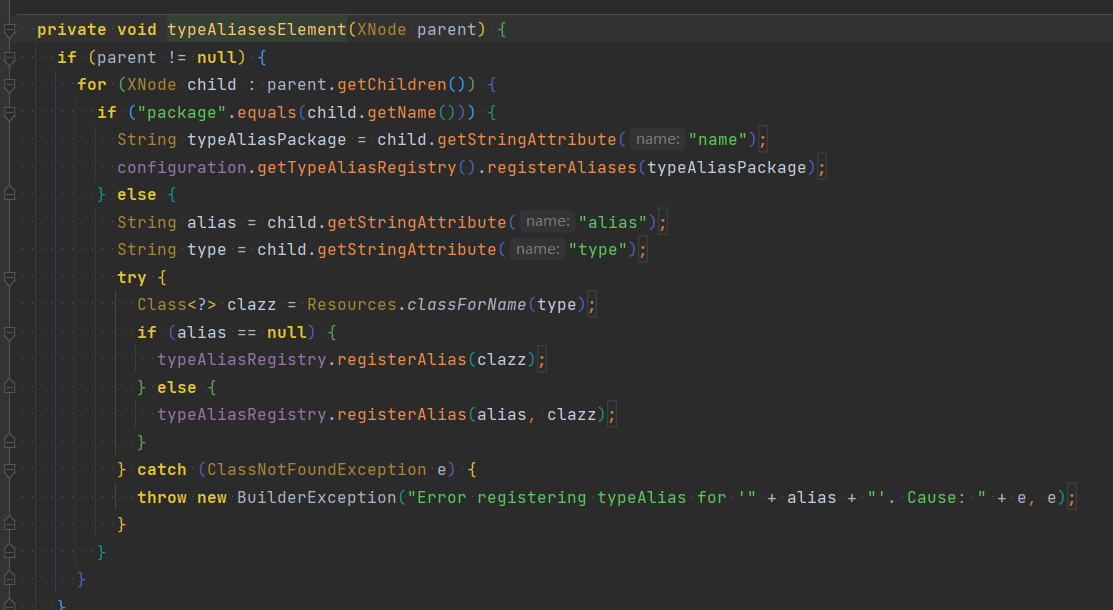
2.2 typeAliasesElement别名设置
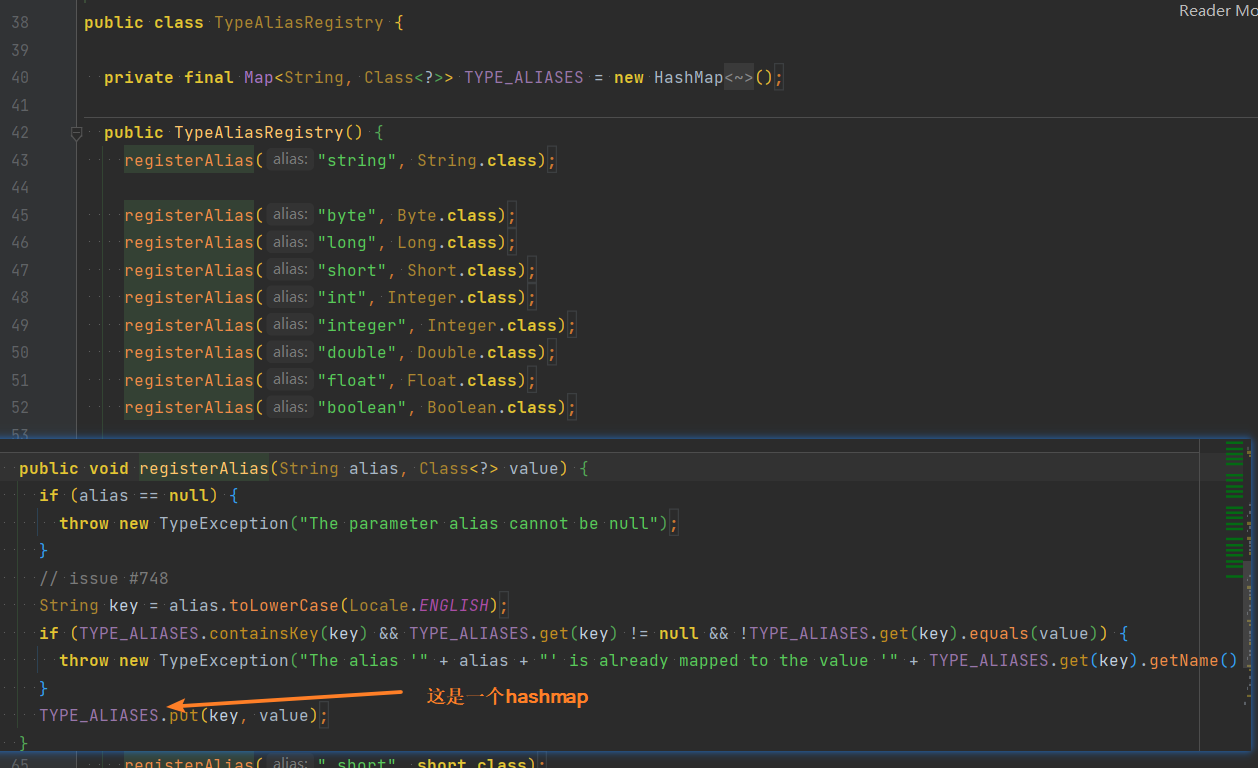
Mybatis别名设置若存在TYPE_ALIASES这个HashMap中,同时里面已经存在很多内置别名,可以直接使用
2.3 数据库相关内容载入
environmentsElement(root.evalNode("environments"));方法将数据库相关信息配置(例如事务,数据库账号密码等)存入enviroment对象,最终和configuration相关联存入其对象中
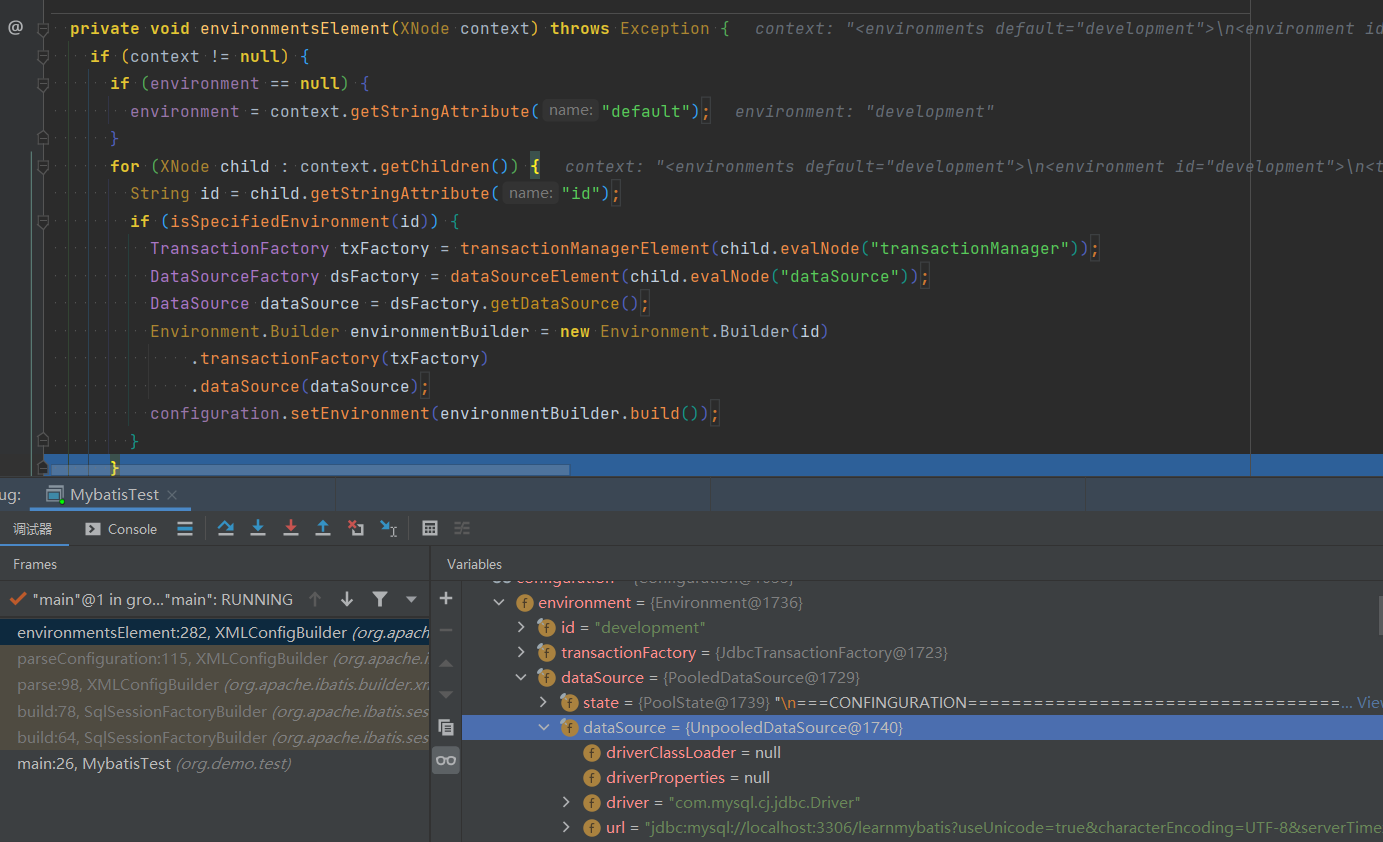
2.4 mapper解析(重要✨)
mybatis-config.xml文件中我们一定会写一个叫做<mapper>节点存放了我们对数据库进行操作的SQL语句,这里就详细详解一下mapper的执行过程
1 | <mappers> |
这是<mappers>标签的几种配置方式,通过这几种配置方式,可以帮助我们更容易理解mappers的解析
1 | private void mapperElement(XNode parent) throws Exception { |
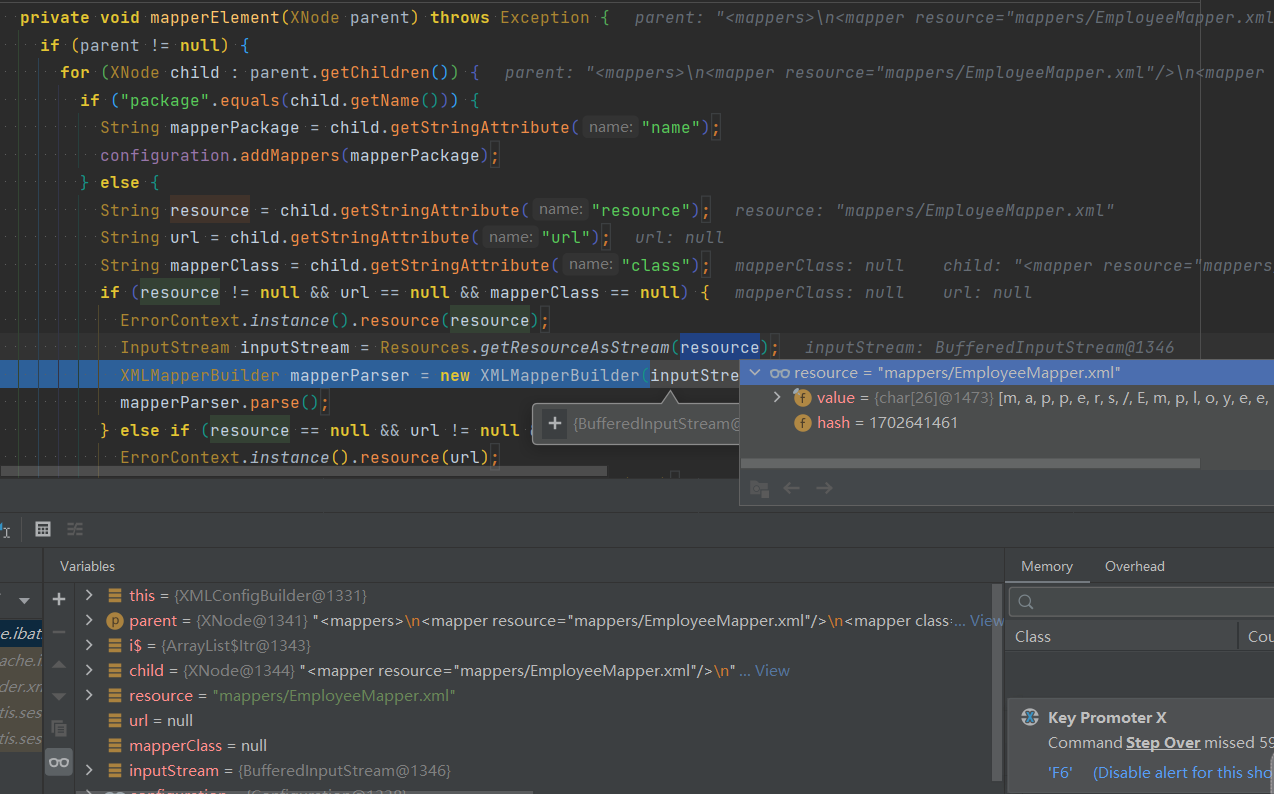
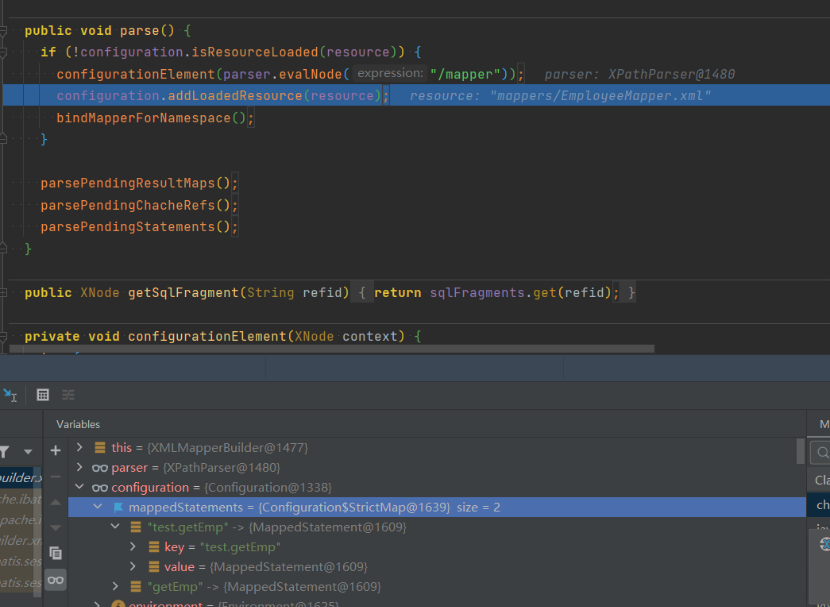
我们的配置文件中写的是通过resource来加载mapper.xml的,所以会通过XMLMapperBuilder来进行解析,我们在进去它的parse()方法。在这个parse()方法中,调用了一个configuationElement代码,用于解析XXXMapper.xml文件中的各种节点,包括<cache>、<cache-ref>、<paramaterMap>(已过时)、<resultMap>、<sql>、还有增删改查节点,和上面相同的是,我们也挑一个主要的来说,因为解析过程都大同小异。
1 | public void parse() { |
这里解析其中一项举例,解析增删改查节点<select> <insert> <update> <delete>,进入buildStatementFromContext(context.evalNodes("select|insert|update|delete"));方法
1 | private void buildStatementFromContext(List<XNode> list) { |
进入statementParser.parseStatementNode();方法,解析里面的xml节点
1 | public void parseStatementNode() { |
具体的MappedStatement对象,这里每一个方法id对应存储一个MappedStatement对象,这样在执行的时候就可以直接通过id获得映射的MappedStatement对象了,即可以直接执行获取mysql结果了
1 | //将刚才获取到的属性,封装成MappedStatement对象 |
3、动态SQL构建
3.1 动态SQL解析
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
OGNL表达示
OGNL全称是对象导航图语言(Object Graph Navigation Language)是一种JAVA表达示语言,可以方便的存取对象属和方法,已用于逻辑判断。其支持以下特性:获取属性属性值,以及子属性值进行逻辑计;表达示中可直接调用方法(如果是无参方法,可以省略括号);通过下标访问数组或集合;遍历集合
3.2 动态SQL脚本
每个动态元素都会有一个与之对应的脚本类,即会产生许多SqlNode脚本如if 对应ifSqlNode、forEarch对应ForEachSqlNode 以此类推下去。同时脚本之间是呈现嵌套关系的,比如if元素中会包含一个MixedSqlNode ,而MixedSqlNode下又会包含1至1至多个其它节点,最后组成一课脚本语法树。最后SqlNode的接口非常简单,就只有一个apply方法,方法的作用就是执行当前脚本节点逻辑,并把结果应用到DynamicContext当中去。
这里要注意下面三个脚本
StaticTextSqlNode表示一段纯静态文本如:select * from userTextSqlNode表示一个通过参数拼装的文本如:select * from ${user}MixedSqlNode表示多个节点的集合

3.3 SqlSource(SQL数据源)
SqlSource 是基于XML解析而来,解析的底层是使用Dom4j 把XML解析成一个个子节点,在通过 XMLScriptBuilder 遍历这些子节点最后生成对应的Sql源。在上层定义上每个Sql映射(MappedStatement)中都会包含一个SqlSource 用来获取可执行Sql(BoundSql)。SqlSource又分为原生SQL源与动态SQL源,以及第三方源

- roviderSqlSource :第三方法SQL源,每次获取SQL都会基于参数动态创建静态数据源,然后在创建BoundSql
- DynamicSqlSource:动态SQL源包含了SQL脚本,每次获取SQL都会基于参数又及脚本,动态创建创建BoundSql
- RawSqlSource:不包含任何动态元素,原生文本的SQL。但这个SQL是不能直接执行的,需要转换成BoundSql
- StaticSqlSource:包含可执行的SQL,以及参数映射,可直接生成BoundSql。前面三个数据源都要先创建StaticSqlSource然后才创建BoundSql
3.4 源码流程
生成SQL语句代码,首先这里会通过<select>节点获取到我们的SQL语句,假设SQL语句中只有${},那么直接就什么都不做,在运行的时候直接进行赋值。而如果扫描到了#{}字符串之后,会进行替换,将#{}替换为 ?。
这里会生成一个GenericTokenParser,这个对象可以传入一个openToken和closeToken,如果是#{},那么openToken就是#{,closeToken就是 },然后通过parse方法中的handler.handleToken()方法进行替换。在这之前由于已经进行过SQL是否含有#{}的判断了,所以在这里如果是只有${},那么handler就是BindingTokenParser的实例化对象,如果存在#{},那么handler就是ParameterMappingTokenHandler的实例化对象。
mapperElement() > mapperParser.parse() > 进入XMLMapperBuilder类 configurationElement() > buildStatementFromContext() > buildStatementFromContext() > statementParser.parseStatementNode();
1 | //XMLStatementBuilder类parseStatementNode方法 |
1 | /*进入createSqlSource方法*/ |
进入sqlSource = new RawSqlSource()>sqlSourceParser.parse()
1 | /*从上面的代码段到这一段中间需要经过很多代码,就不一段一段贴了*/ |
4、构建总结
4.1 总结
MyBatis需要做的就是,先判断这个节点是用来干什么的,然后再获取这个节点的id、parameterType、resultType等属性,封装成一个MappedStatement对象,由于这个对象很复杂,所以MyBatis使用了构造者模式来构造这个对象,最后当MappedStatement对象构造完成后,将其封装到Configuration对象中。
MyBatis需要对配置文件进行解析,最终会解析成一个Configuration对象
- Configuration对象,保存了mybatis-config.xml的配置信息。
- MappedStatement,保存了XXXMapper.xml的配置信息。
但是最终MappedStatement对象会封装到Configuration对象中,合二为一,成为一个单独的对象,也就是Configuration
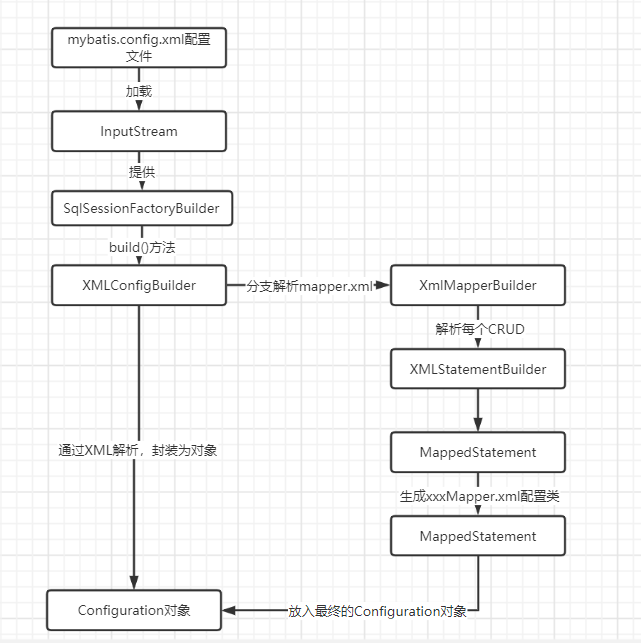
4.2 面试回答
我在开发xxxx项目的时候、使用Mybatis开发项目,我对Mybatis的认识是:它其实是一个orm持久层框架,其实就对jdbc一个封装而得的框架,使用好处其实就可以把jdbc从连接开辟事务管理以及连接关闭和sql执行,对数据的映射pojo整个过程进行一个封装而已。它的整个执行的过程:
- 首先会引入mybatis依赖,然后会定义个xml核心配置文件放入类路径resouces,这个文件里面就描述了数据源、mapper映射、别名的映射、数据类型转换、插件、属性配置等。定义好以后,那么接下就是创建一个SqlSessionFactory对象,但是在创建这个对象之前,我们会进行xml文件的解析,解析过程中会使用SqlSessionFacotoryBuilder里面提供了一个build方法。这个方法的做了一个非常核心的事情:初始化Configuration对象,并且把对应类的属性的对象全部初始化,并且解析核心xml文件
- 把解析核心的xml配置文件的内容放入到Configuration对象中属性中,其中就包括别名的映射,在初始化阶段别名映射会自动注册一些常用的别名。如果我们自己也配置也会自动注册到
Configuration对象的TypeAliasRegistry的map中 - 并且把在配置文件中的数据源和事务解析以后放入到Environment,给后续的执行,提供数据链接和事务管理
- 然后在解析xxxMapper.xml配置文件,根据配置文件解析的规则,会解析里面对应的节点。比如:<select<update<insert <delete<dql <cache<cache-ref <resultMap等,然后把每个解析的节点放入到一个叫MapperStament对象,sql语句就放入到这个对象SqlSource中
- 并且把解析的每一个节点对应的MapperStatment同时放入到Configuration全局的
Map (mapperedStatments)中,以节点的id和命名空间+id做为key,以MapperStatement对象做value,给后续执行提供一个参考和方向
三、Mybatis的执行
1、SqlSession对象生成
1.1 Xml对象直接生成
核心
将SqlSessionFactoryBuilder中通过build方法创建和装配好Configuration对象通过构造函数进行下传,传递到SqlSession中,最后开辟SqlSession会话对象
源码分析
1 | public static void main(String[] args) throws IOException { |
这里进入SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);方法后,Configuration是DefaultSqlSessionFactory的一个属性。而SqlSessionFactoryBuilder在build方法中实际上就是调用XMLConfigBuilder对xml文件进行解析生成Configuration对象,然后注入到SqlSessionFactory中
1 | public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) { |
通过调用sqlSessionFactory.openSession();方法来获取SqlSession对象,而openSession中实际上就是对SqlSession做了进一步的加工封装,包括增加了事务、执行器等
1 | private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { |
1.2 mapper 代理对象的生成
首先需要修改部分文件内容
1 | // 创建EmployeeMapper、代理mapper |
源码分析
从SqlSession的getMapper()方法进入,可以看到这里mapperProxyFactory对象会从一个叫做knownMappers的对象中以type为key取出值,这个knownMappers是一个HashMap,存放了我们的EmployeeMapper对象,而这里的type,就是我们上面写的Mapper接口
1 | //getMapper方法最终会调用到这里,这个是MapperRegistry的getMapper方法 |
对于knownMappers生成,在configuration对象在解析的时候,会调用parse()方法,这个方法内部有一个bindMapperForNamespace方法,而就是这个方法帮我们完成了knownMappers的生成,并且将我们的Mapper接口put进去
1 | public void parse() { |
我们在getMapper之后,获取到的是一个Class,之后的代码就简单了,就是生成标准的代理类了,调用newInstance()方法。到这里,就完成了代理对象(MapperProxy)的创建,很明显的,MyBatis的底层就是对我们的接口进行代理类的实例化,从而操作数据库。
1 | public T newInstance(SqlSession sqlSession) { |
查看动态代理调用的方法逻辑,进入MapperProxy类,发现实现了InvocationHandler接口。
在方法开始代理之前,首先会先判断是否调用了Object类的方法,如果是,那么MyBatis不会去改变其行为,直接返回,如果是默认方法,则绑定到代理对象中然后调用,如果都不是,那么就是我们定义的mapper接口方法了,那么就开始执行。执行方法需要一个MapperMethod对象,这个对象是MyBatis执行方法逻辑使用的,MyBatis这里获取MapperMethod对象的方式是,首先去方法缓存中看看是否已经存在了,如果不存在则new一个然后存入缓存中,因为创建代理对象是十分消耗资源的操作。总而言之,这里会得到一个MapperMethod对象,然后通过MapperMethod的excute()方法,来真正地执行逻辑。
1 | public class MapperProxy<T> implements InvocationHandler, Serializable { |
最后执行逻辑,这里首先会判断SQL的类型:SELECT|DELETE|UPDATE|INSERT,判断SQL类型为SELECT之后,就开始判断返回值类型,根据不同的情况做不同的操作。然后开始获取参数>执行SQL
1 | //execute() 这里是真正执行SQL的地方 |
2、执行SQL前述
进入sqlSession.selectList("test.getEmp");方法,可以发现在调用sqlsession执行的selectList、insert、update、delete的时候,其实就是根据执行的statement名字,到Configuration的mapperStatements对应的map中去找到有没有一个对应的 MapperStatement对象,如果找到就返回这个对象,然后给后续执行一个依据和参考
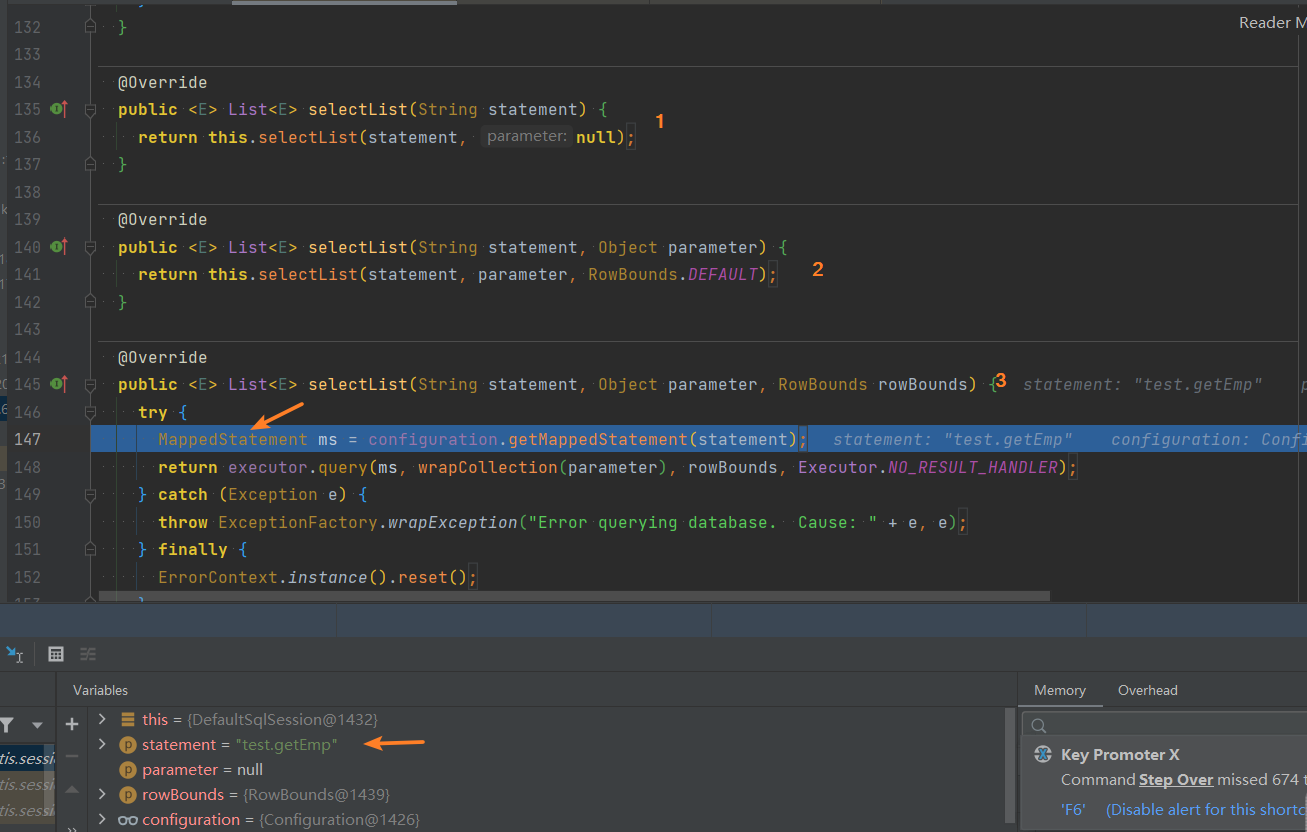
3、执行SQL语句——执行器
3.1 执行架构

- 执行器:Executor, 处理流程的头部,主要负责缓存、事务、批处理。一个执行可用于执行多条SQL。它和SQL处理器是1对N的关系
- Sql处理器:StatementHandler 用于和JDBC打道,比如基于SQL声明Statement、设置参数、然后就是调用Statement来执行。它只能用于一次SQL的执行
- 参数处理器:ParameterHandler,用于解析SQL参数,并基于参数映射,填充至PrepareStatement。同样它只能用于一次SQL的执行
- 结果集处理器:ResultSetHandler,用于读取ResultSet 结果集,并基于结果集映射,封装成JAVA对象。他也只用用于一次SQL的执行
3.2 执行器Executor
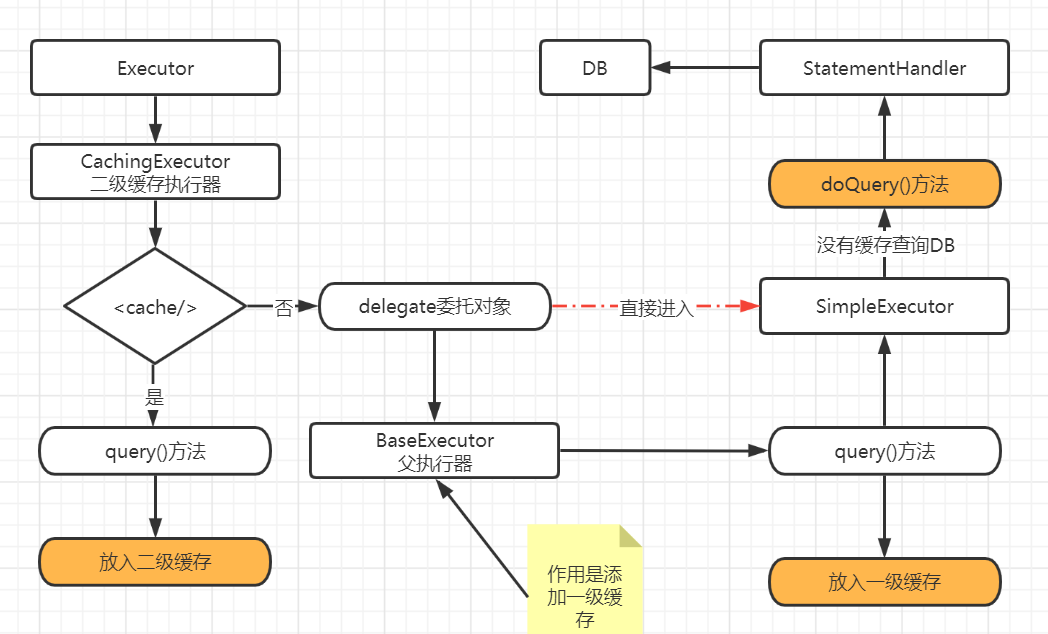
执行器的实现有三种:SimpleExecute、ReuseExecute和BatchExecute,这三种执行器有个抽象的基础执行器BaseExecutor,用于维护缓存和事务;此外通过装饰器形式添加了一个缓存执行器CachingExecutor,用于处理二级缓存
- SimpleExecute 简单执行器(默认)
SimpleExecutor是执行器的默认实现,主要完成了“执行”功能,在利用StatementHandler 完成。每次调用执行方法 都会构建一个StatementHandler,并预行参数,然后执行
默认情况是executor是CachingExecutor。这个执行器是二级缓存的执行器,如果在配置文件xxxxMapper.xml文件中申明了<cache/>节点的话,就是使用CachingExecutor;如果没有,就会委托SimpleExecutor(默认类型是simple,在configuration创建的时候指定)执行器去执行你的SQL语句,然后这里会执行的结果放入loaclCache一级缓存中。
- ReuseExecute 可重用执行器
ReuseExecutor 区别在于他会将在会话期间内的Statement进行缓存,并使用SQL语句作为Key。所以当执行下一请求的时候,不在重复构建Statement,而是从缓存中取出并设置参数,然后执行(参数不同也可以重用) - BatchExecute 批处理执行器
BatchExecutor 顾名思议,它就是用来作批处理的。但会将所 有SQL请求集中起来,最后调用Executor.flushStatements() 方法时一次性将所有请求发送至数据库
3.3 **SimpleExecute **简单执行器源码分析(重点✨)
执行SQL的核心方法就是selectList,即使是selectOne,底层实际上也是调用了selectList方法,然后取第一个而已
1 |
|
selectList内部调用了Executor对象执行SQL语句,首先进入的是CachingExecutor执行器,若没有开启二级缓存,那么委托简单执行器
1 | public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { |
首先MyBatis在查询时,不会直接查询数据库,而是会进行二级缓存的查询,由于二级缓存的作用域是namespace,也可以理解为一个mapper,所以还会判断一下这个mapper是否开启了二级缓存,如果没有开启,则进入一级缓存继续查询。
1 | //一级缓存查询 |
如果一级缓存localCache里查到了,那么直接就返回结果了,如果一级缓存没有查到结果,那么最终会进入数据库进行查询
1 | //数据库查询 |
总结,一级缓存和二级缓存的key是一样的,一级缓存默认开启,二级缓存需要设置开启。这里CacheExecutor使用的是装饰者模式,即在不改变原有类结构和继承的情况下,通过包装原对象去扩展一个新功能。
4、执行SQL语句——数据库查询
执行流程
4.1 StatementHandler介绍
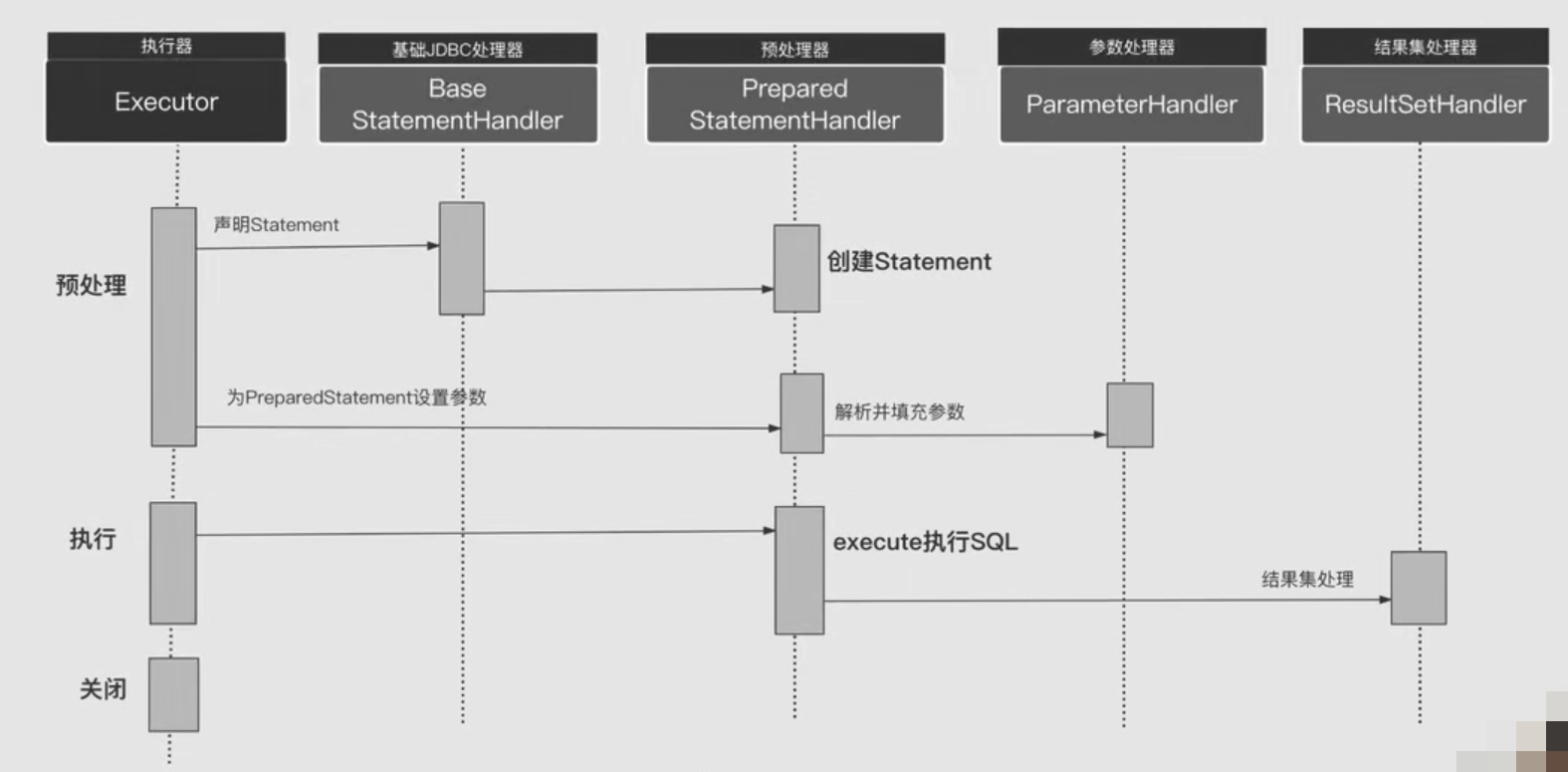
StatementHandler即为JDBC处理器,基于JDBC构建JDBC Statement并设置参数,然后执行Sql。每调用会话当中一次SQl,都会有与之相对应的且唯一的Statement实例,一个SQL请求会经过会话,然后是执行器,最由StatementHandler执行jdbc最终到达数据库,这三者之间比例是1:1:n。
StatementHandler接口定义了JDBC操作的相关方法如下,
1 | // 基于JDBC 声明Statement |
StatementHandler 有三个子类SimpleStatementHandler、PreparedStatementHandler、CallableStatementHandler,分别对应JDBC中的Statement、PreparedStatement、CallableStatement。
4.2 参数处理和转换
参数处理即将Java Bean转换成数据类型。总共要经历过三个步骤,ParamNameResolver(参数转换)、ParameterHandler(参数映射)、TypeHandler(参数赋值)
参数转换
所有转换逻辑均在ParamNameResolver中实现
1 | ("select * from employee where id = #{id}") |
- 单个参数的情况下且没有设置@param注解会直接转换,勿略SQL中的引用名称
- 多个参数情况:优先采用@Param中设置的名称,如果没有则用参数序号代替 即"param1、parm2等"
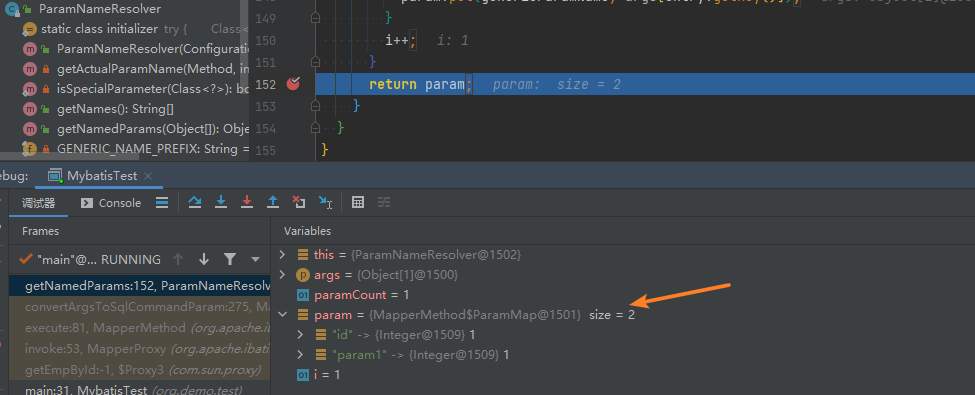
参数映射
映射是指Map中的key如何与SQL中绑定的参数相对应。以下这几种情况
- 单个原始类型:直接映射,勿略SQL中引用名称
- Map类型:基于Map key映射
- Object:基于属性名称映射,支持嵌套对象属性访问
参数赋值
通过TypeHandler 为PrepareStatement设置值,通常情况下一般的数据类型MyBatis都有与之相对应的TypeHandler
4.3 结果集封装
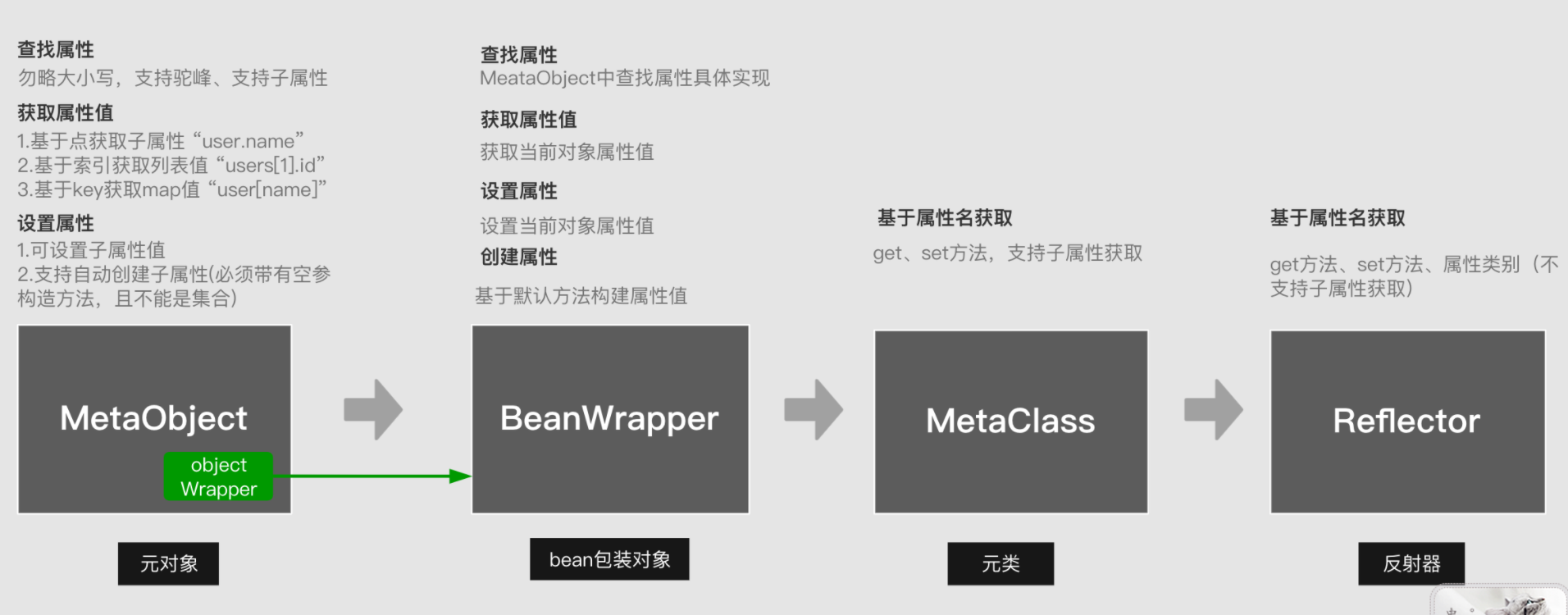
MetaObject相当于一个工具类,里面还包括分词器等,可以参考MetaObject详解
读取ResultSet数据,并将每一行转换成相对应的对象。用户可在转换的过程当中可以通过ResultContext来控制是否要继续转换,转换后的对象都会暂存在ResultHandler中最后统一封装成list返回给调用方,结果集转换中99%的逻辑DefaultResultSetHandler 中实现。整个流程可大致分为以下阶段:
- 读取结果集
- 遍历结果集当中的行
- 创建对象
- 填充属性
1 | //PreparedStatementHandler,这里是真正查询 |
在SQL执行阶段,MyBatis已经完成了对数据的查询,那么现在还存在最后一个问题,那就是结果集处理,换句话来说,就是将结果集封装成对象,这里会创建一个处理结果集的对象
1 | //DefaultResultSetHandler |
调用handleRwoValues()方法进行行数据的处理
1 | //处理行数据 |
我们可以看到这个方法会通过遍历参数列表从而通过metaObject.setValue(mapping.property, value);对返回对象进行赋值,所有的赋值操作在内部都是通过一个叫ObjectWrapper的对象完成的,先看看中代码的metaObject.setValue()方法
1 | //MetaObject类,工具类 |
objectWrapper有两个实现:BeanWrapper和MapWrapper,如果是自定义类型,那么就会调用BeanWrapper的set方法。MapWrapper的set方法实际上就是将属性名和属性值放到map的key和value中,而BeanWrapper则是使用了反射,调用了Bean的set方法,将值注入。
1 | //MapWrapper的set方法 |
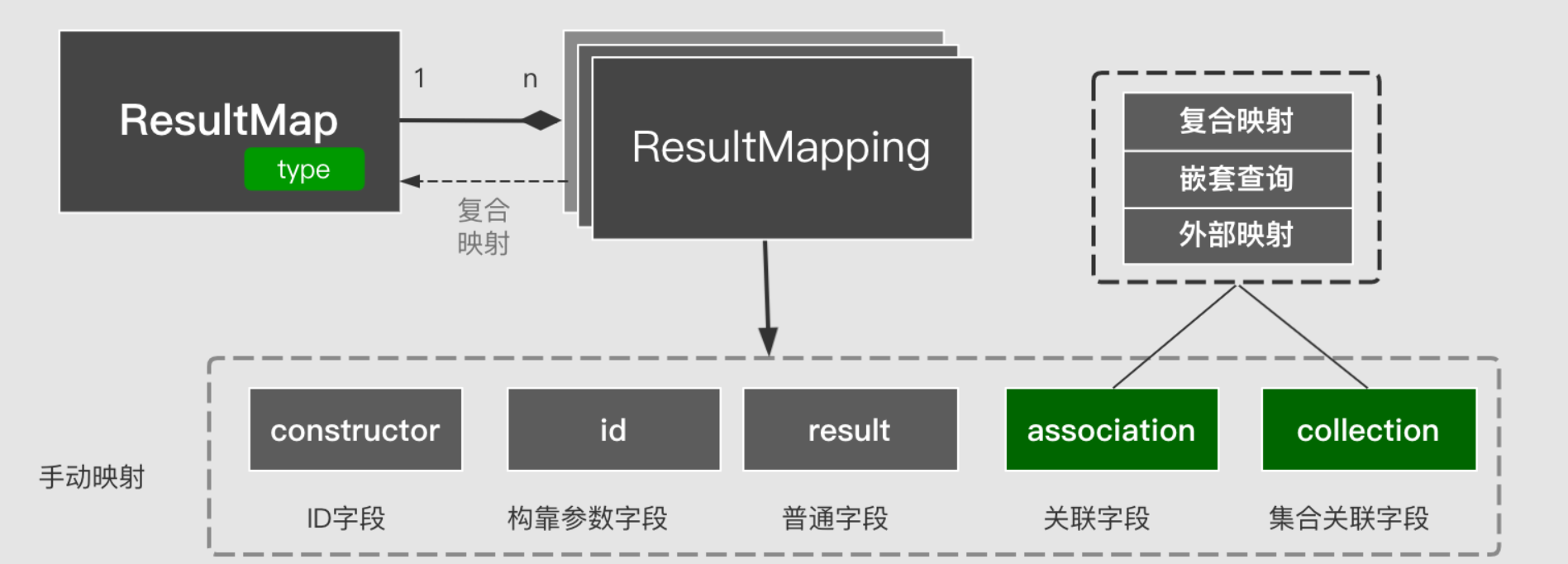
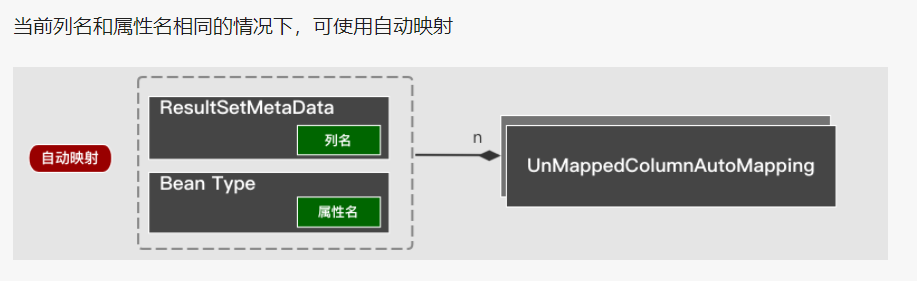
4.4 结果集映射
映射是指返回的ResultSet列与Java Bean 属性之间的对应关系。通过ResultMapping进行映射描述,在用ResultMap封装成一个整体,包括手动映射和自动映射
| property | 属性名(必填) |
|---|---|
| column | 列名(必填) |
| jdbcType | jdbc类型(可自动推导) |
| javaType | java类型(可自动推导) |
| typeHandler | 类型处理器(可自动推导) |
4.5 懒加载
懒加载是为了改善在映射结果集解析对象属性时,大量的嵌套子查询的并发效率问题,当设置懒加载后,只有在使用指定属性时才会触发子查询,从而实现分散SQL请求的目的
配置方式
在mybais主配置文件中配置开启侵入式加载和深度加载,也可以在xml映射文件中配置fetchType,有效值为 lazy 和 eager。 指定属性后,将在映射中忽略全局配置参数 lazyLoadingEnabled,使用属性的值
1 | <!--配置直接延迟加载,默认是false--> |
内部原理
代理过程发生在结果集解析创建对象之后(DefaultResultSetHandler.createResultObject),如果对应的属性设置了懒加载,则会通过**ProxyFactory **创建代理对象,该对象继承自原对象,然后将对象的值全部拷贝到代理对象,并设置相应MethodHandler(原对象直接抛弃)
通过对Bean的动态代理,重写所有属性的getXxx方法,代理之后Bean会包含一个MethodHandler,内部在包含一个Map用于存放待执行懒加载,执行前懒加载前会移除。LoadPair用于针对反序列化的Bean准备执行环境。ResultLoader用于执行加载操作,执行前如果原执行器关闭会创建一个新的。
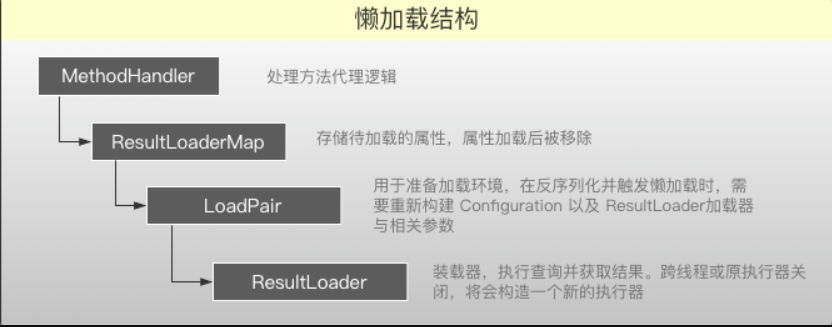
4.6 嵌套映射
映射是指返回的ResultSet列与Java Bean 属性之间的对应关系。通过ResultMapping进行映射描述,在用ResultMap封装成一个整体。映射分为简单映射与复合嵌套映射,联合查询分为一对一查询和一对多查询

流程说明
所有映射流程的解析都是在DefaultResultSetHandler当中完成。主要方法如下:
handleRowValuesForNestedResultMap()
嵌套结果集解析入口,在这里会遍历结果集中所有行。并为每一行创建一个RowKey对象。然后调用getRowValue()获取解析结果对象。最后保存至ResultHandler中(注:调用getRowValue前会基于RowKey获取已解析的对象,然后作为partialObject参数发给getRowValue)
getRowValue()
该方法最终会基于当前行生成一个解析好对象。具体职责包括,1.创建对象、2.填充普通属性和3.填充嵌套属性。在解析嵌套属性时会以递归的方式在调用getRowValue获取子对象。最后一步4.基于RowKey 暂存当前解析对象(如果partialObject参数不为空 只会执行 第3步。因为1、2已经执行过了)
applyNestedResultMappings()
解析并填充嵌套结果集映射,遍历所有嵌套映射,然后获取其嵌套ResultMap。接着创建RowKey 去获取暂存区的值。然后调用getRowValue 获取属性对象。最后填充至父对象(如果通过RowKey能获取到属性对象,它还是会去调用getRowsValue,因为有可能属下还存在未解析的属性)
MyBatis循环依赖问题
mybatis解决循环依赖主要是利用一级缓存和内置的queryStack标识。mybatis中BaseExecutor执行器对一级缓存进行管控,利用queryStack标识对最终结果进行处理,一级缓存对没有操作的查询缓存key进行空参填充,在嵌套子查询中会判断是否命中一级缓存,然后将其添加到延迟队列(非懒加载),直到整个查询结束再对其进行延迟队列的加载,填充所有数据
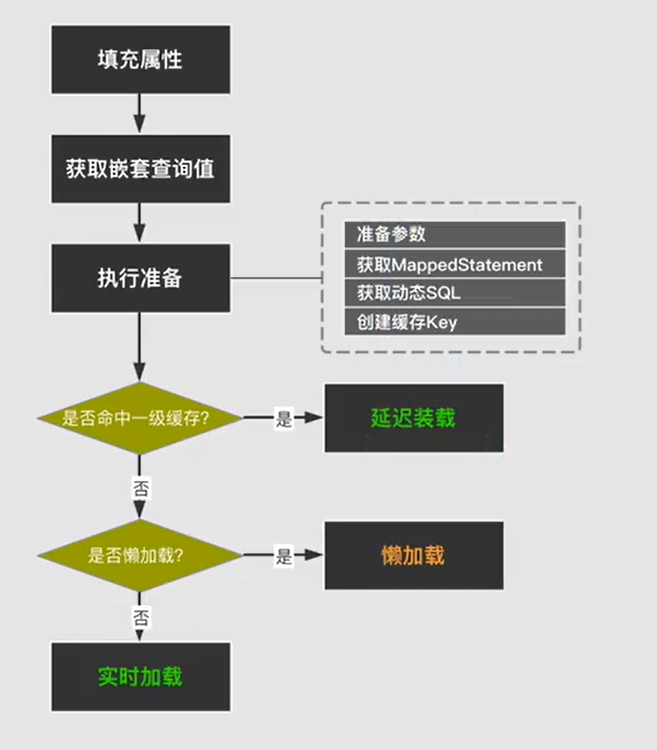
其源码主要在DefaultResultSetHandler类中,方法调用手动映射,具体为applyPropertyMappings>getPropertyMappingValue>getNestedQueryMappingValue>ResultLoader - 结果集加载器>再次进入BaseExecutor的query中,对queryStack进行累加,直到跳出整个查询
四、Mybatis的缓存
1、缓存概述
myBatis中存在两个缓存,一级缓存和二级缓存
- 一级缓存:也叫做会话级缓存,生命周期仅存在于当前会话,不可以直接关关闭。但可以通过
flushCache和localCacheScope对其做相应控制。 - 二级缓存:也叫应用级缓存,缓存对象存在于整个应用周期,而且可以跨线程使用。
2、一级缓存
2.1 缓存命中与清空
缓存命中参数
- SQL与参数相同
- 同一个会话
- 相同的MapperStatement ID
- RowBounds行范围相同
触发清空缓存
- 手动调用clearCache,注意clearLocalCache 不是清空某条具体数据,而是清当前会话下所有一级缓存数据
- 执行提交回滚(commit、Rolback)
- 执行任意增删改update
- 配置flushCache=true
- 缓存作用域为Statement(即子查询,子查询依赖一级缓存)
2.2 集成Spring一级缓存失效
因为Spring 对SqlSession进行了封装,通过SqlSessionTemplae ,使得每次调用Sql,都会重新构建一个SqlSession,解决方法是
- 开启事务,因为一旦开启事务,Spring就不会在执行完SQL之后就销毁SqlSession,因为SqlSession一旦关闭,事务就没了,一旦我们开启事务,在事务期间内,缓存会一直存在
- 使用二级缓存

3、二级缓存
3.1 简介
二级缓存也称作是应用级缓存,与一级缓存不同的,是它的作用范围是整个应用,而且可以跨线程使用。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据,在流程上是先访问二级缓存,在访问一级缓存。二级缓存的更新,必须是在会话提交之后,同时要提交之后才能命中缓存
3.2 二级缓存使用
缓存空间声明
二级默认缓存默认是不开启的,需要为其声明缓存空间才可以使用,通过**@CacheNamespace** 或 在xml配置**
| 配置 | 说明 |
|---|---|
| implementation | 指定缓存的存储实现类,默认是用HashMap存储在内存当中 |
| eviction | 指定缓存溢出淘汰实现类,默认LRU ,清除最少使用 |
| flushInterval | 设置缓存定时全部清空时间,默认不清空。 |
| size | 指定缓存容量,超出后就会按eviction指定算法进行淘汰 |
| readWrite | true即通过序列化复制,来保证缓存对象是可读写的,默认true |
| blocking | 为每个Key的访问添加阻塞锁,防止缓存击穿 |
| properties | 为上述组件,配置额外参数,key对应组件中的字段名。 |
缓存其它配置
除@CacheNamespace 还可以通过其它参数来控制二级缓存
| 字段 | 配置域 | 说明 |
|---|---|---|
| cacheEnabled | 在mybatis设置 | 二级缓存全局开关,默认开启 |
| useCache | <select | update |
| flushCache | <select | update |
注意:若*Mapper.xml和mapper接口同时设置SQL查询,并同时配置了缓存,那么两个缓存空间是不一致,需要用缓存引用ref使用同一个缓存空间
3.3 责任链设计
这里MyBatis抽像出Cache接口,其只定义了缓存中最基本的功能方法:
- 设置缓存
- 获取缓存
- 清除缓存
- 获取缓存数量
然后上述中每一个功能都会对应一个组件类,并基于装饰者加责任链的模式,将各个组件进行串联。在执行缓存的基本功能时,其它的缓存逻辑会沿着这个责任链依次往下传递。
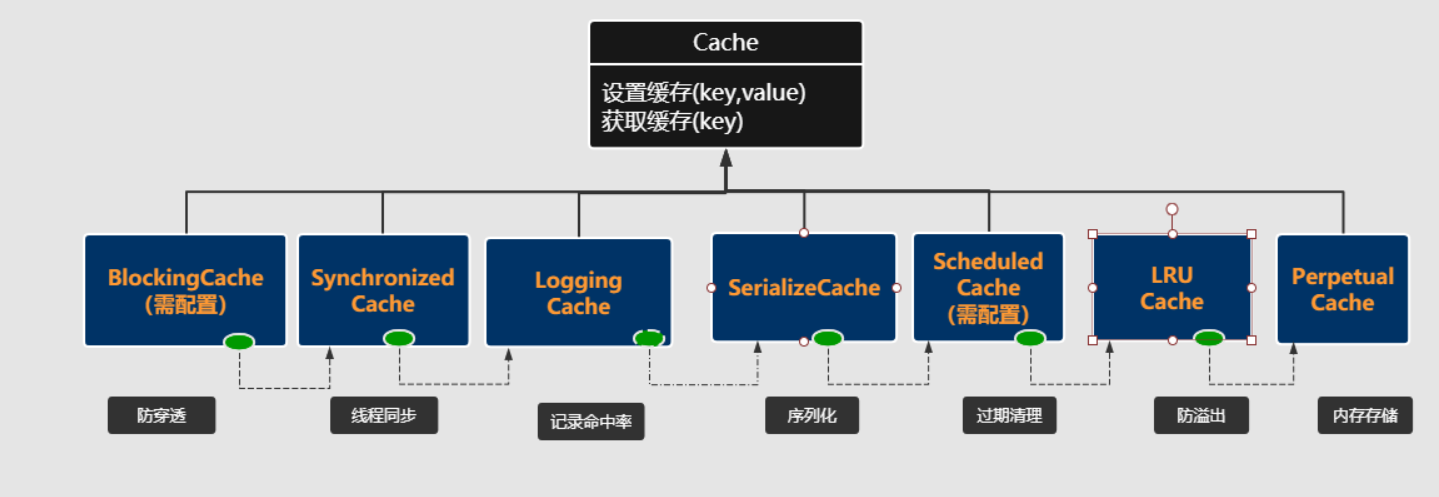
3.4 执行流程
原本会话是通过Executor实现SQL调用,这里基于装饰器模式使用CachingExecutor对SQL调用逻辑进行拦截,以嵌入二级缓存相关逻辑。这里SqlSession会话可以对应多个暂存区,而多个暂存区对应一个缓存空间
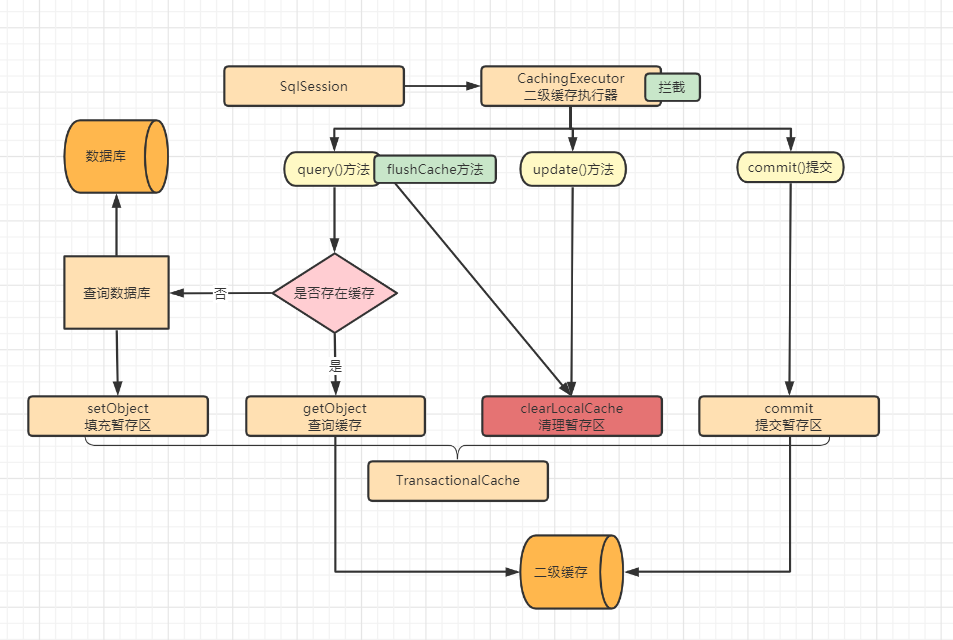
查询操作query
当会话调用query() 时,会基于查询语句、参数等数据组成缓存Key,然后尝试从二级缓存中读取数据。读到就直接返回,没有就调用被装饰的Executor去查询数据库,然后在填充至对应的暂存区。
请注意,这里的查询是实时从缓存空间读取的,而变更,只会记录在暂存区
更新操作update
当执行update操作时,同样会基于查询的语句和参数组成缓存KEY,然后在执行update之前清空缓存。这里清空只针对暂存区,同时记录清空的标记,以便当会话提交之时,依据该标记去清空二级缓存空间。
如果在查询操作中配置了flushCache=true ,也会执行相同的操作。
提交操作commit
当会话执行commit操作后,会将该会话下所有暂存区的变更,更新到对应二级缓存空间去。
3.5 缓存源码事务分析
这个类是MyBatis用于缓存事务管理的类
1 | public class TransactionalCacheManager { |
TransactionalCacheManager中封装了一个Map,用于将事务缓存对象缓存起来,这个Map的Key是我们的二级缓存对象,而Value是一个叫做TransactionalCache。
- 其中在getObject()方法中存在两个分支:如果发现缓存中取出的数据为null,那么会把这个key放到entriesMissedInCache中,这个对象的主要作用就是将我们未命中的key全都保存下来,防止缓存被击穿,并且当我们在缓存中无法查询到数据,那么就有可能到一级缓存和数据库中查询,那么查询过后会调用putObject()方法,这个方法本应该将我们查询到的数据put到真实缓存中,但是现在由于存在事务,所以暂时先放到entriesToAddOnCommit中;如果发现缓存中取出的数据不为null,那么会查看事务提交标识(clearOnCommit)是否为true,如果为true,代表事务已经提交了,之后缓存会被清空,所以返回null,如果为false,那么由于事务还没有被提交,所以返回当前缓存中存的数据
- 事务提交成功时有以下几步:清空真实缓存、将本地缓存(未提交的事务缓存 entriesToAddOnCommit)刷新到真实缓存、将所有值复位
- 回滚步骤:清空真实缓存中未命中的缓存、将所有值复位
1 | public class TransactionalCache implements Cache { |
3.6 使用经验
二级缓存不能存在一直增多的数据
由于二级缓存的影响范围不是SqlSession而是namespace,所以二级缓存会在你的应用启动时一直存在直到应用关闭,所以二级缓存中不能存在随着时间数据量越来越大的数据,这样有可能会造成内存空间被占满。
二级缓存有可能存在脏读的问题(可避免)
由于二级缓存的作用域为namespace,那么就可以假设这么一个场景,有两个namespace操作一张表,第一个namespace查询该表并回写到内存中,第二个namespace往表中插一条数据,那么第一个namespace的二级缓存是不会清空这个缓存的内容的,在下一次查询中,还会通过缓存去查询,这样会造成数据的不一致。所以当项目里有多个命名空间操作同一张表的时候,最好不要用二级缓存,或者使用二级缓存时避免用两个namespace操作一张表。
五、Mybatis插件
1、核心原理
插件机制是为了对MyBatis现有体系进行扩展而提供的入口。底层通过动责任链模式+ JDK动态代理实现。插件的核心是拦截四个接口的子对象,拦截以后会进入到intercept方法中进行业务的处理,而Invocation对象可以获取到四个接口的具体
- Executor:执行器
- StatementHandler:JDBC处理器
- ParameterHandler:参数处理器
- ResultSetHandler:结果集处理器
1 | //注意interceptorChain.pluginAll()方法 |
Interceptor类核心方法代码
1 | public interface Interceptor { |
2、源码分析
2.1 插件类创建
首先创建自定义插件
1 | ({( |
在config.xml 中添加插件配置,注意配置顺序
1 | <plugins> |
2.2 源码分析
构建图
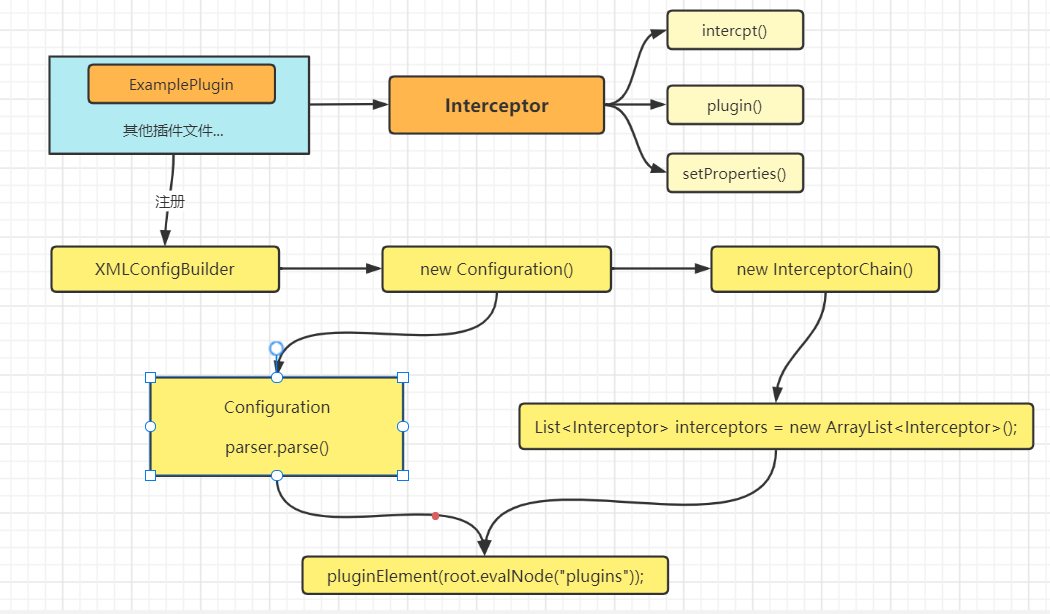
核心代码
插件对象的创建InterceptorChain
1 | //SqlSessionFactoryBuilder类的build方法 |
XMLConfigBuilder会实例化一个Configuration对象,在创建Configuration对象,会调用构造函数,InterceptorChain对象的创建,就是在Configuration的构造函数中进行了初始化,如InterceptorChain interceptorChain = new InterceptorChain();
进入InterceptorChain 代码
1 | public class InterceptorChain { |
在parse()方法解析的时候,parseConfiguration()中解析插件pluginElement(root.evalNode("plugins"))
1 | //XMLConfigBuilder类 |
插件的执行流程
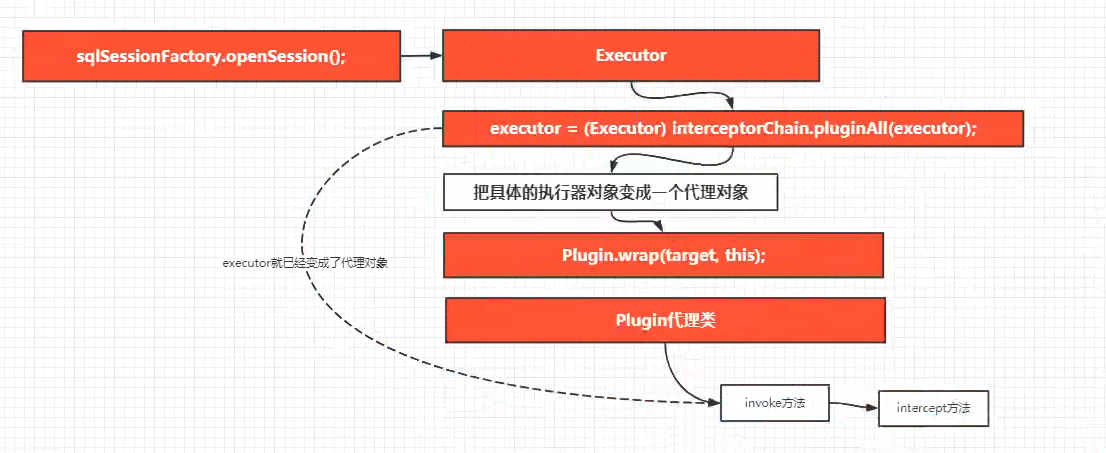
2.3 源码总结
Mybatis插件使用机制就是:** jdk动态代理+责任链的设计模式**。插件的运行和注册会分为几个阶段:
1、定义阶段,定义插件类然后实现Interceptor接口,覆盖这个接口三个方法,分别是:plugin方法,interceptor方法,setProperties方法
- intercept方法:如果自定插件实现Interceptor覆盖intercept方法,这个方法是一个核心方法,里面参数Invocation对象,这个对象可以通过反射调度原来的对象的方法。
- plugin方法:target被拦截的对象。它的作用:把拦截的target对象变成一个代理对象
- setProperties方法:允许plugin在注册的时候,配置插件需要的参数,这个参数可以在mybats的核心配置文件中注册插件的时候,一起配置到文件中
2、注册阶段,写入到mybatis配置文件中,如果是spring整合myabtis化,就使用配置类来进行插件的注册
3、同时在定义的时候,会通过@Intercepts注解和签名,来告诉插件具体要拦截那些类执行的方法,mybatis对四个接口实现类都会进行拦截
4、运行和执行阶段,定义了执行器的插件后,在初始化sqlsession的时候会确定一个执行器,而执行器在创建的时候,会调用executor = (Executor)interceptorChain.pluginAll(executor)。这个方法的作用就是把执行器对象变成一个代理对象,而代理对象的生成,是通过插件的的plugin方法进行生成和创建,具体的话是通过代理类Plugin中的wrap方法创建而生成,生成executor代理对象之后,当代理执行器执行方法的时候,就进入Plugin代理类中invoke方法中进行业务处理
3、分页插件举例
3.1 分页插件原理
首先设定一个Page类,其包含total、size、index 3个属性,在Mapper接口中声明该参数即表示需要执行自动分页逻辑。总体实现步骤包含3个:
- 检测是否满足分页条件
- 自动求出当前查询的总行数
- 修改原有的SQL语句 ,添加 limit offset 关键字。
3.2 检测是否满足分页条件
分页条件是 1.是否为查询方法,2.查询参数中是否带上Page参数。在intercept 方法中可直接获得拦截目标StatementHandler ,通过它又可以获得BoundSql 里面就包含了SQL 和参数。遍历参数即可获得Page。
1 | // 带上分页参数 |
3.3 查询总行数
实现逻辑是 将原查询SQL作为子查询进行包装成子查询,然后用原有参数,还是能过原来的参数处理器进行赋值。关于执行是采用JDBC 原生API实现。MyBatis执行器,从而绕开了一二级缓存。
1 | private int selectCount(Invocation invocation) throws SQLException { |
3.4 修改原SQL
最后一项就是修改原来的SQL,前面我是可以拿到BoundSql 的,但它没有提供修改SQL的方法,这里可以采用反射强行为SQL属性赋值。也可以采用MyBatis提供的工具类SystemMetaObject来赋值
1 | String newSql= String.format("%s limit %s offset %s", boundSql.getSql(),page.getSize(),page.getOffset()); |
参考文章:

