
实时数据同步之Maxwell和Canal
实时数据同步之Maxwell和Canal
一、概述
1、实时同步工具概述
1.1 Maxwell 概述
Maxwell 是由美国 Zendesk 开源,用 Java 编写的 MySQL 实时抓取软件。 实时读取MySQL 二进制日志 Binlog,并生成 JSON格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序
注意:1.30.0版本后不在支持JDK8
1.2 Canal概述
Canal 是用 Java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前。Canal 主要支持了 MySQL 的 Binlog 解析,解析完成后才利用 Canal Client 来处理获得的相关数据。(数据库同步需要阿里的 Otter 中间件,基于 Canal)
2、数据同步工作原理
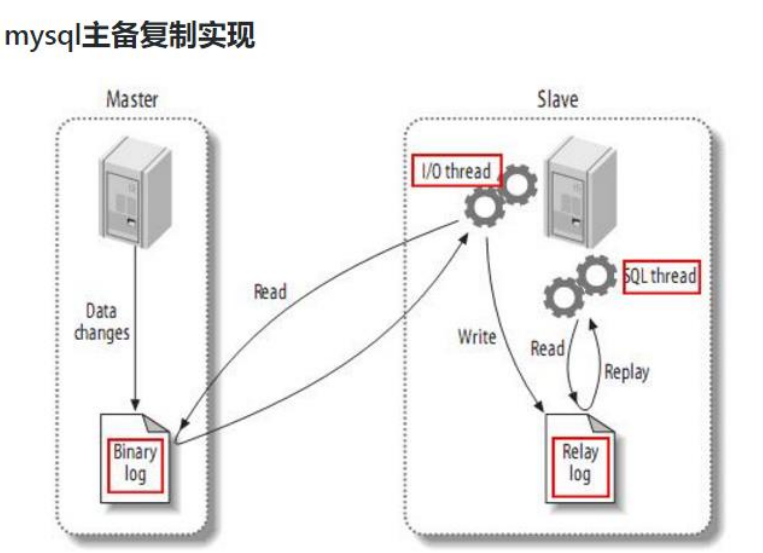
2.1 MySQL 主从复制过程
具体可以参考:ShardingSphere数据库中间件基础学习
- Master 主库将改变记录,写到二进制日志(binary log)中
- Slave 从库向 mysql master 发送 dump 协议,将 master 主库的 binary log events 拷贝到它的中继日志(relay log);
- Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
2.2 两种工具工作原理
就是把自己伪装成 Slave,假装从 Master 复制数据
3、MySQL 的 binlog详解
3.1 什么是 binlog
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的 DDL 和 DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
- MySQL Replication 在 Master 端开启 binlog,Master 把它的二进制日志传递给 slaves 来达到 master-slave 数据一致的目的
- 自然就是数据恢复了,通过使用 mysqlbinlog 工具来使恢复数据。二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件
3.2 binlog 的开启
- 找到 MySQL 配置文件的位置
- Linux:
/etc/my.cnf如果/etc 目录下没有,可以通过locate my.cnf查找位置 - Windows: \my.ini
- 在 mysql 的配置文件下,修改配置在[mysqld] 区块,设置/添加
log-bin=mysql-bin这个表示 binlog 日志的前缀是 mysql-bin,以后生成的日志文件就是 mysql-bin.000001的文件后面的数字按顺序生成,每次 mysql 重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号
3.3 binlog 的分类设置
mysql binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW。在配置文件中可以选择配binlog_format= statement|mixed|row。Maxwell 想做监控分析,选择 row 格式比较合适
-
statement
语句级,binlog 会记录每次一执行写操作的语句。相对 row 模式节省空间,但是可能产生不一致性,比如
update test set create_date=now();如果用 binlog 日志进行恢复,由于执行时间不同可能产生的数据就不同。优点: 节省空间 缺点: 有可能造成数据不一致。 -
row
行级, binlog 会记录每次操作后每行记录的变化。优点:保持数据的绝对一致性。因为不管 sql 是什么,引用了什么函数,他只记录执行后的效果。缺点:占用较大空间
-
mixed
混合级别,statement 的升级版,一定程度上解决了 statement 模式因为一些情况而造成的数据不一致问题。默认还是 statement,在某些情况下,譬如:当函数中包含 UUID() 时;包含 AUTO_INCREMENT 字段的表被更新时;执行 INSERT DELAYED 语句时;用 UDF 时;会按照 ROW 的方式进行处理 优点:节省空间,同时兼顾了一定的一致性。缺点:还有些极个别情况依旧会造成不一致,另外 statement 和 mixed 对于需要对binlog 监控的情况都不方便。
4、Maxwell和Canal对比
| 对比 | Canal | Maxwell |
|---|---|---|
| 语言 | java | java |
| 数据格式 | 格式自由 | json |
| 采集数据模式 | 增量 | 全量/增量 |
| 数据落地 | 定制 | 支持 kafka 等多种平台 |
| HA | 支持 | 支持 |
5、环境安装
需要安装mysql,kafka,zookeeper,具体的可以参考之前的博客文章
这里讲解开启mysql的binLog日志
1 | sudo vim /etc/my.cnf |
注:MySQL 生成的 binlog 文件初始大小一定是 154 字节,然后前缀是 log-bin 参数配置的,后缀是默从.000001,然后依次递增。除了 binlog 文件文件以外,MySQL 还会额外生产一个.index 索引文件用来记录当前使用的 binlog 文件
二、Maxwell 使用
1、Maxwell 安装部署
1.1 下载安装
1 | # 因为1.30开始不支持jdk8,所以用这个 |
1.2 初始化 Maxwell 元数据库
1 | # 在 MySQL 中建立一个 maxwell 库用于存储 Maxwell 的元数据 |
1.3 Maxwell 进程启动
1 | # ============Maxwell 进程启动方式有如下两种======== |
2、Maxwell入门案例
2.1 监控 Mysql 数据并在控制台打印
1 | # 运行 maxwell 来监控 mysql 数据更新 |
创建对应的mysql语句,查看控制台
1 | # 向 mysql 的 test_maxwell 库的 test 表插入一条数据,查看 maxwell 的控制台输出 |
2.2 监控 Mysql 数据输出到 kafka
简单接入
1 | # 启动 zookeeper 和 kafka |
然后就是kafka 主题数据的分区控制,在公司生产环境中,我们一般都会用 maxwell 监控多个 mysql 库的数据,然后将这些数据发往 kafka 的一个主题 Topic,并且这个主题也肯定是多分区的,为了提高并发度。那么如何控制这些数据的分区问题,就变得至关重要,实现步骤如下:在公司生产环境中,我们一般都会用 maxwell 监控多个 mysql 库的数据,然后将这些数据发往 kafka 的一个主题 Topic,并且这个主题也肯定是多分区的
1 | # 修改 maxwell 的配置文件,定制化启动 maxwell 进程 |
1 | # 手动创建一个 3 个分区的 topic,名字就叫做 maxwell3 |
2.3 监控 Mysql 指定表数据输出控制台
运行 maxwell 来监控 mysql 指定表数据更新
1 | # 运行 maxwell 来监控 mysql 指定表数据更新 |
2.4 监控 Mysql 指定表全量数据输出控制台,数据初始化
Maxwell 进程默认只能监控 mysql 的 binlog日志的新增及变化的数据,但是Maxwell 是支持数据初始化的,可以通过修改 Maxwell 的元数据,来对 MySQL 的某张表进行数据初始化,也就是我们常说的全量同步。具体操作步骤如下:需求:将 test_maxwell 库下的 test2 表的四条数据,全量导入到 maxwell 控制台进行打印
1 | # 修改Maxwell的元数据,触发数据初始化机制,在 mysql 的 maxwell 库中 bootstrap表中插入一条数据,写明需要全量数据的库名和表名 |
还有一个方法是使用maxwell-bootstrap脚本,前提是已经启动了maxwell,否则会被阻塞
1 | /opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/module/maxwell/config.properties |
2.5 群起脚本
一个启动脚本,可以参考
1 |
|
三、Canal使用
1、Canal 的下载和安装
1.1 下载安装
1 | # https://github.com/alibaba/canal/releases |
1.2 mysql创建canal用户
1 | mysql -uroot -p123456 |
1.3 修改 canal.properties 的配置
1 | cd /opt/module/canal/conf |
说明:这个文件是 canal 的基本通用配置,canal 端口号默认就是 11111,修改 canal 的输出 model,默认 tcp,改为输出到 kafka
多实例配置如果创建多个实例,通过前面 canal 架构,我们可以知道,一个 canal 服务中可以有多个 instance,conf/下的每一个 example 即是一个实例,每个实例下面都有独立的配置文件。默认只有一个实例 example,如果需要多个实例处理不同的 MySQL 数据的话,直接拷贝出多个 example,并对其重新命名,命名和配置文件中指定的名称一致,然后修改canal.properties 中的 canal.destinations=实例1,实例2,实例3
1 | ################################################# |
1.4 修改 instance.properties
我们这里只读取一个 MySQL 数据,所以只有一个实例,这个实例的配置文件在conf/example 目录下
1 | cd /opt/module/canal/conf/example |
2、实时监控测试
2.1 TCP 模式测试
首先创建项目,引入依赖
1 | <dependencies> |
通用监视类–CanalClient
1 | public class CanalClient { |
然后在服务端启动canal:bin/startup.sh,修改数据库进行测试
2.2 Kafka 模式测试
修改 canal.properties 中 canal 的输出 model,默认 tcp,改为输出到 kafka
1 | ################################################# |
修改 Kafka 集群的地址
1 | ################################################## |
修改 instance.properties 输出到 Kafka 的主题以及分区数。注意:默认还是输出到指定 Kafka 主题的一个 kafka 分区,因为多个分区并行可能会打乱 binlog 的顺序 , 如 果 要 提 高 并 行 度 , 首 先 设 置 kafka 的 分 区 数 >1, 然 后 设 置canal.mq.partitionHash 属性
1 | # mq config |
然后启动测试
1 | cd /opt/module/canal/ |

