
Spring之秒传、断点续传、分片上传和压缩
一、大文件上传简介
1、秒传
通俗的说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了
2、分片上传
2.1 介绍
分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件
2.2 应用场景
-
大文件上传
-
网络环境环境不好,存在需要重传风险的场景
3、断点续传
3.1 介绍
断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。
3.2 应用场景
断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传
3.3 核心逻辑
在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。
3.4 实现流程步骤
方案一,常规步骤
-
将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
-
初始化一个分片上传任务,返回本次分片上传唯一标识;
-
按照一定的策略(串行或并行)发送各个分片数据块;
-
发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件。
方案二、更高效
-
前端(客户端)需要根据固定大小对文件进行分片,请求后端(服务端)时要带上分片序号和大小
-
服务端创建conf文件用来记录分块位置,conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的0,已上传的就是Byte.MAX_VALUE 127(这步是实现断点续传和秒传的核心步骤)
-
服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。
二、普通方式
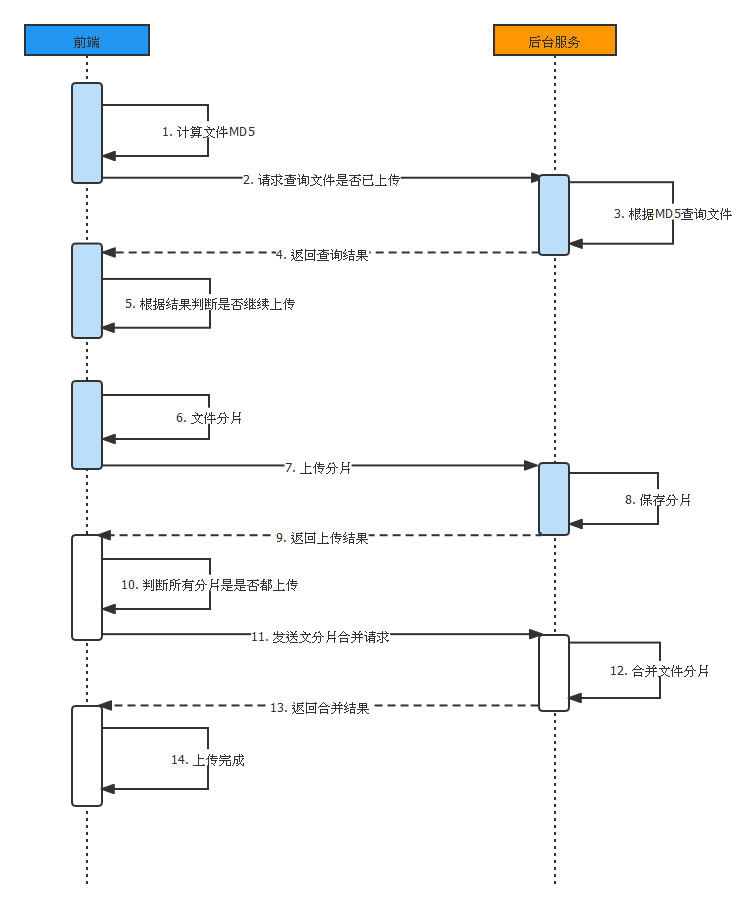
1、整体思路
1.1 前端部分思路
所有请求都使用ajax
-
文件控件选择后,计算文件唯一码,调用接口查询文件是否存在。文件存在则判断分片是否上传完成,已完成显示秒传信息;
-
点击上传按钮后,再查询一次文件是否存在,来获取文件分片信息。文件不存在,那么起始分片为1;文件存在,那么获取起始分片为已上传+1;
-
ajax串行调用分片上传方法,成功后进行分片序号+1的分片上传,直到最终已上传分片序号和总分片数量相同。
1.2 后端部分思路
-
首先利用数据库存储文件信息,包括文件物理地址,分片接收进程和对应的md5码。利用md5码可以判断当前上传文件是否在服务器中存在(实现秒传),利用分片接收Index可以判断现在应该上传。
-
前端ajax获取文件存在与否的信息,几种情况:
-
不存在,则创建数据库记录,成功后调用分片1的上传
-
存在,Index和总分片数量相同,秒传成功显示结果
-
存在,但index小于总分片数量,调用分片index的上传
-
-
分片在前端根据分片Index计算起点末尾,slice切割,ajax调用上传传到服务器并存储。当前分片传递成功,ajax接收success信息,串行进行index+1的分片的上传
2、环境准备
本次Demo项目是前后端一起,前端部分使用了内嵌的thymeleaf,根据链接跳转自动访问resource/static/下的静态文件,如果前后端分离可以参考,首先引入依赖
1 | <dependency> |
配置文件
1 | spring: |
数据库设计
1 | DROP TABLE IF EXISTS `segment_file`; |
项目结构图
3、前端实现
上传界面
1 |
|
上传Js代码
1 | // 控制文件分片和上传 |
4、后端实现
4.1 持久化类与全局返回类
1 |
|
4.2 Mapper接口
Mapper接口,这边使用注解进行mybatis sql语句的配置
1 |
|
4.3 文件工具类
1 | // 工具类 |
4.4 Service分片服务类
比较关键的业务类,包括文件存在确认,文件记录创建,文件信息更新,分片存储,分片合并和分片文件删除功能的实现
1 | // 分片存储 |
4.5 Controller类
主要是两个方法,一个是判断当前文件上传状况,主要就是想在前端选中文件后就调用一下,显示文件上传状态,这样就能实现秒传功能的效果了。第二个就是上传分片功能
1 | /** |
5、总结
因为是默认串行调用,文件已上传分片信息直接用当前上传的分片序号覆盖。如果要并行实现的话,数据库中可能需要存储一个总分片数量大小长度的字符串,用来记录上传进度(状态压缩),比如111011,表示6个分片,分片4未上传,这样就能并行上传分片了
代码地址:https://github.com/LXT2017/JavaLearnProject/tree/main/file-segment
三、进阶方案
1、介绍
这篇文章写的也不错,使用的是Vue+SpringBoot大文件上传,可以参考:SpringBoot 实现大文件分片上传、断点续传及秒传
前端部分可以使用百度或者使用第三方的上传组件;后端用两种方式实现文件写入,一种是用RandomAccessFile(参考:https://blog.csdn.net/dimudan2015/article/details/81910690);另一种是使用MappedByteBuffer(参考:https://www.jianshu.com/p/f90866dcbffc)
使用该种方法要注意每一个分块的记录,因为通过偏移量存储文件的方式是直接操作源文件的,并不会生成一块块的分片文件,分片文件使用Mysql或者Redis进行记录,最后传输成功后记录完整的文件信息。
2、核心代码介绍
文件操作核心模板类代码
1 | 4j |
RandomAccessFile实现方式
1 | (mode = UploadModeEnum.RANDOM_ACCESS) |
MappedByteBuffer实现方式
1 | (mode = UploadModeEnum.MAPPED_BYTEBUFFER) |
四、Gzip 压缩超大 json 对象上传(加餐)
1、概述
1.1 业务背景
一个通过Json传值的接口需要传大量数据,例如一个广告接口,内部系统有一个广告保存接口,需要ADX那边将投放的广告数据进行保存供后续使用,其中一个字段存放了广告渲染的HTML代码,因此,对与请求数据那么大的接口我们肯定是需要作一个优化,否则太大的数据传输有以下几个弊端:
- 占用网络带宽,而有些云产品就是按照带宽来计费的,间接浪费了钱
- 传输数据大导致网络传输耗时
1.2 实现思路
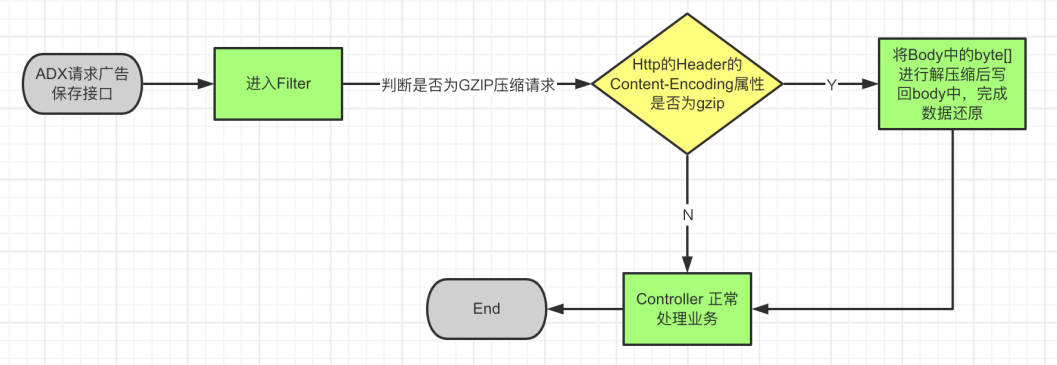
请求广告保存接口时先将Json对象字符串进行GZIP压缩,那请求时传入的就是压缩后的数据,而GZIP的压缩效率是很高的,因此可以大大减小传输数据,而当数据到达广告保存接口前再将传来的数据进行解压缩,还原成JSON对象就完成了整个GZIP压缩数据的请求以及处理流程
- 对与需要占用而外的CPU计算资源来说,内部系统属于IO密集型应用,因此用一些CPU资源来换取更快的网络传输其实是很划算的
- 使用过滤器在请求数据到达Controller之前对数据进行解压缩处理后重新写回到Body中,避免影响Controller的逻辑,代码零侵入
- 而对于改造接口的同时是否会影响到原来的接口这一点可以通过 HttpHeader 的
Content-Encoding=gzip属性来区分是否需要对请求数据进行解压缩
1.3 前置知识
- Http 请求结构以及Content-Encoding 属性
- gzip压缩方式
- Servlet Filter
- HttpServletRequestWrapper
- Spring Boot
- Java 输入输出流
1.4 实现流程
2、基础知识介绍
过滤器和拦截器的文章可以参考:
SpringBoot 过滤器、拦截器、监听器对比及使用场景!
SpringBoot的过滤器和拦截器和全局异常处理
Filter过滤器和Interceptor拦截器配置和生命周期
2.1 过滤器与拦截器介绍
-
Listener 监听
Listener 可以监听 web 服务器中某一个事件操作,并触发注册的回调函数。通俗的语言就是在 application,session,request 三个对象创建/消亡或者增删改属性时,自动执行代码的功能组件。
-
Servlet
Servlet 是一种运行服务器端的 java 应用程序,具有 独立于平台和协议的特性,并且可以动态的生成 web 页面,它工作在 客户端请求与服务器响应 的中间层。
-
过滤器 Filter
Filter对用户请求进行预处理,接着将请求交给 Servlet 进行处理并生成响应,最后 Filter 再对服务器响应进行后处理。Filter 是可以复用的代码片段,常用来转换 HTTP 请求、响应和头信息。Filter 不像 Servlet,它不能产生响应,而是只修改对某一资源的请求或者响应。
-
拦截器 Interceptor
类似面向切面编程(AOP)中的切面和通知,我们通过动态代理对一个 service() 方法添加通知进行功能增强。比如说在方法执行前进行初始化处理,在方法执行后进行后置处理。拦截器的思想和AOP 类似,区别就是拦截器只能对 Controller 的 HTTP 请求进行拦截
2.2 Filter 与 Interceptor 区别
- Filter 是基于函数回调的,而 Interceptor 则是基于 Java 反射 和 动态代理。
- Filter 依赖于 Servlet 容器,遵循Servlet规范,而 Interceptor 依赖于spring容器,遵循Spring规范。
- Filter 对几乎 所有的请求 起作用,但过滤器的控制比较粗,只能在请求进来时进行处理,对请求和响应进行包装,而 Interceptor 只对 Controller 对请求起作用,但更精细的控制,可以在controller对请求处理之前或之后被调用,也可以在渲染视图呈现给用户之后调用
2.3 执行顺序
- Filter 过滤请求处理
- Interceptor 拦截请求处理
- Aspect(切面) 拦截处理请求(这里不赘述)
- 对应的 HandlerAdapter 处理请求
- Aspect(切面) 拦截响应请求(这里不赘述)
- Interceptor 拦截响应处理
- Interceptor 的最终处理
- Filter 过滤响应处理
3、核心代码
3.1 配置controller
创建一个SpringBoot项目,先编写一个接口,功能很简单就是传入一个Json对象并返回,以模拟将广告数据保存到数据库
1 | 4j |
3.2 压缩工具类
1 | public class GZIPUtils { |
3.3 编写过滤器
首先编写一个自定义过滤器
1 | 4j |
实现RequestWrapper实现解压和写回Body的逻辑
1 | /** |
注册过滤器,也可以用注解@WebFilter(value = "/*",filterName ="AFilter" )实现
1 |
|
4、测试
注意一个大坑:千万不要直接将压缩后的byte[]当作字符串进行传输,否则你会发现压缩后的请求数据竟然比没压缩后的要大得多🐶!一般有两种传输压缩后的byte[]的方式:
- 将压缩后的byet[]进行base64编码再传输字符串,这种方式会损失掉一部分GZIP的压缩效果,适用于压缩结果要存储在Redis中的情况
- 将压缩后的byte[]以二进制的形式写入到文件中,请求时直接在body中带上文件即可,用这种方式可以不损失压缩效果
测试的时候注意在请求头Headers里带上Content-Type=application/json和Content-Encoding=gzip,带上gzip就是就会进行解压,不带就正常
参考文档:
https://blog.csdn.net/qq_41733192/article/details/123783292
https://cloud.tencent.com/developer/article/1541199

